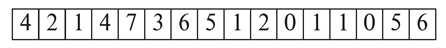立即注册
登录
搜索
前端开发
后端开发
虚幻引擎
U3D引擎
体感研发
数据库
论坛
BBS
本版
帖子
用户
麒麟软控
»
论坛
›
麒麟软控
›
数据库
›
数据库学习笔记(05): Storage and File Structure ...
返回列表
发新帖
数据库学习笔记(05): Storage and File Structure
永不磨灭的
永不磨灭的
当前离线
积分
3
1
主题
1
帖子
3
积分
新手上路
新手上路, 积分 3, 距离下一级还需 47 积分
新手上路, 积分 3, 距离下一级还需 47 积分
积分
3
发消息
发表于 2023-3-25 15:04:17
|
显示全部楼层
Cylinder柱面
Platter盘面
Track磁道
Sector扇区
物理地址:CHS:柱面、读写头(盘面)、扇区
逻辑地址:Block
Optimization
缓冲技术:磁盘读取的数据暂存在内存缓冲区中以满足将来的访问需要
预读技术:当一个磁盘块被访问时,相同磁道上的数据一起被读到内存缓冲区中。好处是什么?不好之处呢?从顺序读和随机读的两个方面分析
调度技术:根据磁盘的运转机理,如果需要访问的数据块分布在不同的柱面上,可以针对磁盘的机器臂进行优化,使机械臂按照移动距离最短的顺序发出访问请求,通常使用
电梯算法
。
文件组织技术:为了减少块的访问时间,按照与预期数据访问方式最接近的方式组织磁盘上的块。例如通常顺序访问日志文件,这时可以将日志文件的所有数据块存储在连续的柱面上。可回忆操作系统中文件系统部分的内容以及教材437页的介绍。
非易失性缓冲区:利用non-volatile RAM(例如利用备用电源支持的RAM),当数据库请求写一个数据块到磁盘上时,磁盘控制器将这个数据块写到non-volatile RAM上,然后通知写操作完成,只有当non-volatile RAM满了才会有一个延迟。当non-volatile RAM满了或磁盘访问空闲时间的时候,磁盘控制器将数据块写入到磁盘相应的目标位置,减少了机械臂的移动。异步写的方式。
日志磁盘技术:一种专门用于写顺序日志的磁盘,所有访问都是都是顺序的,根本上消除了寻道时间,一次可以连续读多个数据块。支持日志磁盘的文件系统称作日志文件系统,也可以在没有日志磁盘的情况下实现。数据库系统实现自己的日志。为了保证系统的安全性,在应用系统层面通常也要实现日志。有一些专门的实现日志的框架。日志对以系统恢复很重要。
Redundant Arrays of Independent Disks
通过
冗余
提高可靠性
通过
并行
提高性能
RAID级别的含义:通过
条带
与
校验位
结合,在成本和性能之间权衡,以较低成本提供数据冗余的方案
Striping
Bit-level striping
– split the bits of each byte across multiple disks
Block-level striping
– with
n
disks, block
i
of a file goes to disk (
i
mod
n
) + 1(最常用的方法)
一格表示sector,block=4sector,segment=2block,strip=4segment。strip是有四块磁盘地址空间统一管理
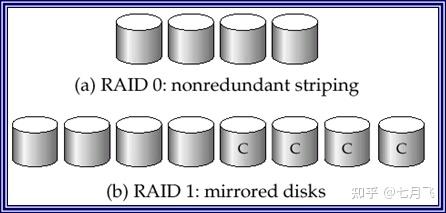
RAID 0
Block striping
块级拆分但
没有冗余
。在块级做
条带
,没有冗余。即多个磁盘只作条带化来存储数据,不冗余存储数据。
RAID 1+0
Mirrored disks
块级拆分的镜像磁盘。磁盘通过块
条带
化做镜像,
冗余
存储数据
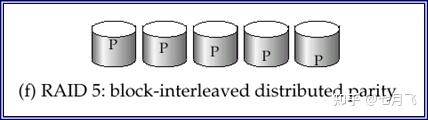
RAID 5
Block-Interleaved Distributed Parity
采用了块级拆分且
校验信息分布式
存储,即数据和其他的数据的校验信息可以存储在同一个磁盘上,但是该数据自己的校验信息不能和自己存储在用一块磁盘上
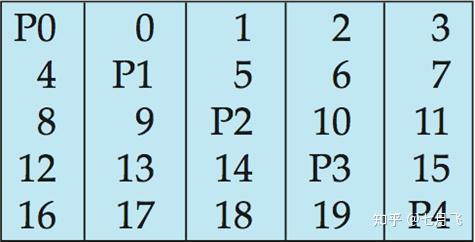
一共5块磁盘做RAID,P0~P4表示纠错位(校验信息),数据块按照(
n mod
5) + 1的方式存储在5块盘上,相应数据块的校验信息存储在另外一块盘上
IO代价大
,写一次读两块写两块,写为主则不建议(因为写之前要先看校验信息,邂逅的数据去计算新的校验值)
RAID5
至少3块盘
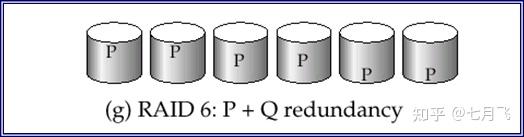
RAID 6
P+Q Redundancy scheme
在RAID 5的基础上进行了改进,采用
双校验
,可靠性更高,但成本也更高,应用不广泛
Choice of RAID level
成本
性能
磁盘故障时的性能
磁盘故障后数据重建的性能
RAID 0 仅在数据安全不重要时使用,例如:可以从其他来源快速恢复数据
Level 6很少使用,因为Level 1和Level 5为几乎所有应用提供足够的安全性。常用1或者5
Level 1 提供的写入性能比Level 5 好得多
Level 5 至少需要 2 个块读取和 2 个块写入来写入单个块,而Level 1 只需要 2 个块写入
Level 1优先用于high update新环境(如日志磁盘)。Level 1 的存储成本高于Level 5
RAID 1比RAID 5 的存储成本高。因为镜像需要额外的存储,需要额外的资金投入到存储上。大量数据和低更新率的应用程序
Level 1是所有其他应用程序的首选
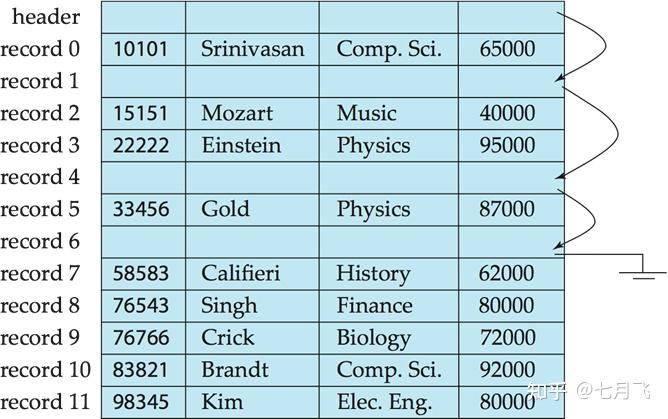
Fixed-Length Records
可能会跨block存储
删除数据有几种方法,删除第i个记录时
第i记录的后续记录依次向前移动
第n个记录移动到第i个位置
不需要移动记录,删除记录的位置做标记,记下来。当有新的记录增加时(通常的应用增加数据的操作比删除数据的操作频繁),放到这个被删除记录的位置上。用
Free List
记录这些位置
在文件的开始的地方,预留一些字节作为文件头(file header),记录文件的一些信息:被删除的第一个记录的地址。然后第一个记录的位置存储第二个被删除的记录的地址,依次类推,所有被删除记录的space都被记录了下来,形成一个free list
Variable-Length Records
变长记录在数据库系统中以下面几种方式出现:
一个文件中存储多种记录类型的记录;
允许一个记录的一个或多个字段是变长的;
允许数据类型是array或multiset类型的记录
表示一个变长记录包括两个部分:
开始部分是
定长
属性的数据,如日期、数值型、定长字符串
第二部分是
变长
属性的数据,如变长字符串,则在记录的开始部分存储表示
(offset, length)
对, 其中
offset
表示记录中该属性的数据开始的位置,length表示某记录变长属性的实际字节数
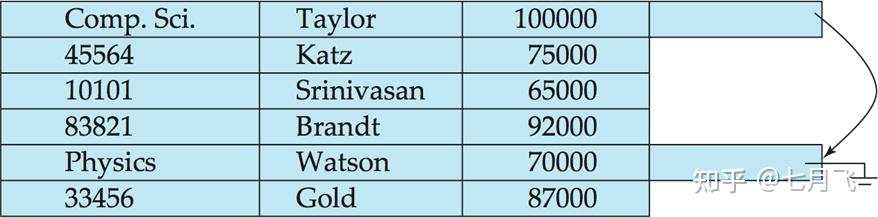
一个变长记录如上所示:前面三个矩形是offset-length对,指向后面的三个变长值(ID:10101,name:Srinivasan,dept:Comp.Sci)。salary:65000是定长。20位置处有一个占用了1个Byte的Null Bitmap,表示哪一个值是Null
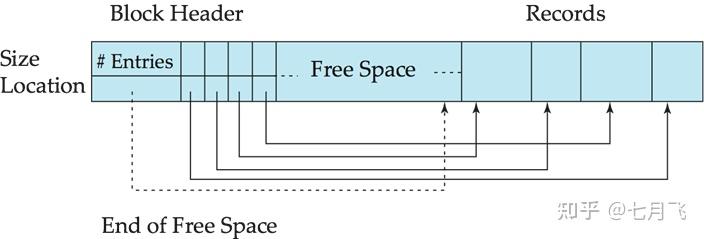
Slotted-Page Structure 分槽页式结构
每个block的头部记录了以下信息:
Record个数
块的free space的末端地址
每个记录的位置和大小
插入记录时,总是从空闲空间的尾部开始,并在块首部登记插入记录的开始位置和大小
删出记录时,释放所占用空间,在块首部的该记录大小作标记(如-1),然后左边的记录
移
过来填补,使实际记录仍然紧连。 同时修改块首部的信息
这是一个数据块中的多个变长记录的组织。最左边是块的头,第一个slot记录了
记录的个数
和块的free space的
末端地址
;接下来的slot分别记录了每个记录的
位置和size
。Free space之后是每一个
具体的记录
。
Organization of Records in Files
关系是一组记录。给定一组记录,如何在文件中组织它们
Heap File Organization
记录可以放置在文件中有free space的
任何位置
记录在分配后通常
不会移动
在文件中高效找到free space,而不是顺序搜索文件的所有块,很重要
free-space map
通常放在内存中去看每一个块还有多少占比的空间剩余
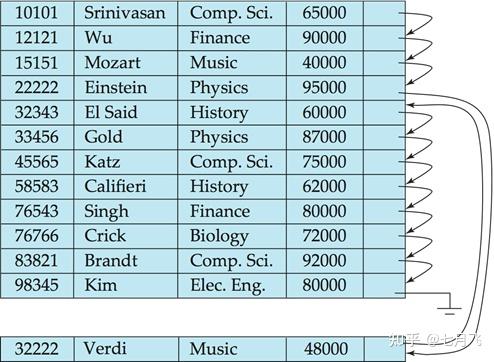
Sequential File Organization
顺序文件组织是为了高效处理按照某个属性值的顺序排序的记录
为了减少顺序文件处理的块访问数量,在物理上(块空间中)按照search key的顺序或者尽可能接近search key的顺序存储记录
删除数据:使用
指针链表
形式,修改链表指针完成
插入数据:首先定位插入记录的位置上(保持顺序),如果所在的数据块有空闲空间(之前删除记录留下来的),就插入新的记录;否则在新的
溢出块
中插入新的记录
需要时不时组织文件让它有序,代价大
Multitable Clustering File Organization 多表聚集
在每一个块中存储两个或多个关系的相关西路的文件结构。如果两个表
经常join
,这样提高查询效率
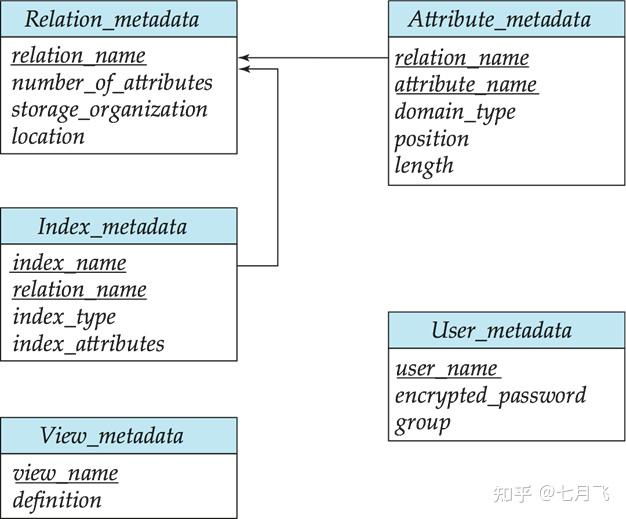
Data Dictionary Storage
关于关系的数据称为“
元数据
”。关于关系的关系模式和其他元数据存储在称作“
数据字典
”或系统目录的结构中。系统必须存储的信息包括:
关于关系的信息:关系的名字、每个关系的属性名和类型、在数据库上定义的视图和视图的定义、完整性约束(如,key)
用户和审计信息:授权用户名、用户的授权和账户信息、用户密码等信息
统计数据和描述数据:每个关系的元组个数、每个关系的存储方法
物理文件组织信息:
如果关系存储在操作系统文件中,则记录每个关系的名字
如果所有关系存储在一个文件中,则将记录每个关系的位置,将每个关系中记录的存储块记在链表这样的数据结构中。
文件中的记录是如何组织的,例如hash还是顺序,还是树结构
索引信息:索引的名字、被索引的关系的名字、在其上定义索引的属性、索引类型等
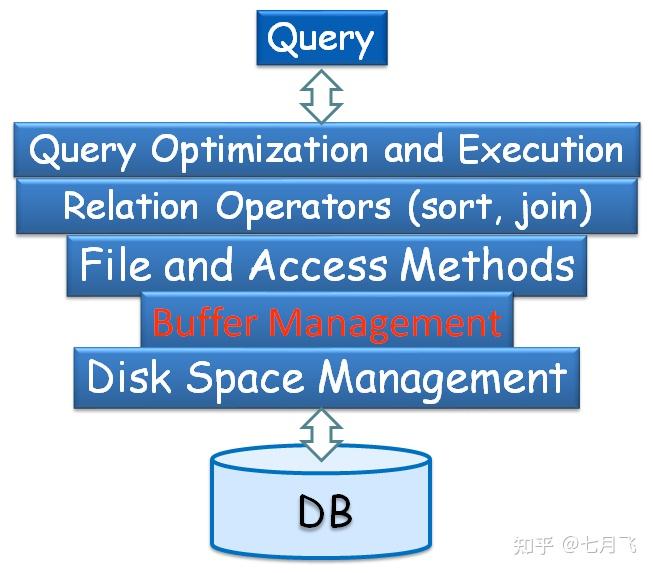
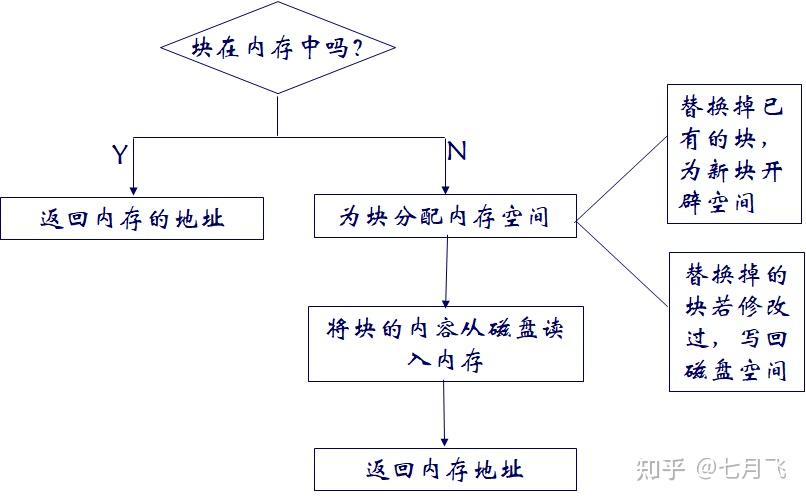
DBMS and Storage Access
块:磁盘空间固定大小的存储单元,数据存储分配和传输的单位。DBMS不依赖OS的块管理,而是自己实现了一套
Buffer:内存中用于存储磁盘块拷贝的部分空间。
Buffer manager:负责在内存中分配buffe的子系统
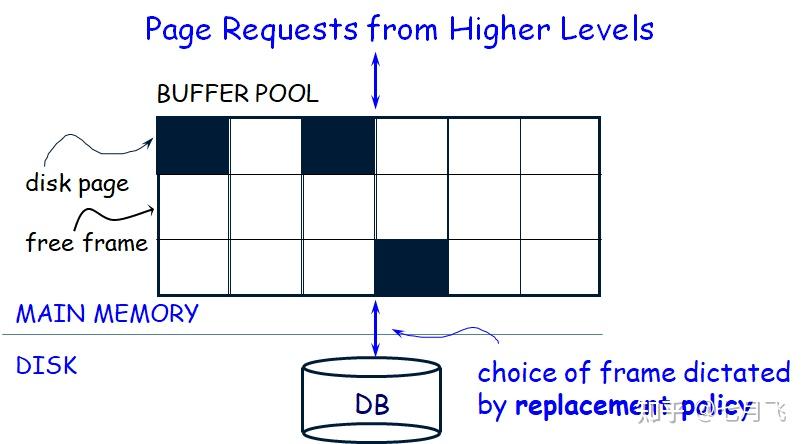
Buffer Management in DBMS
Buffer Manager Technology
buffer替换策略:类似OS的LRU
大量的join,LRU不好
Pinned block:为了能够使数据库系统从系统崩溃中
恢复
,
限制
一些块写回磁盘,这些块称作被定住的块。
Forced output block:为了保证数据的
持久性
存储,需要强制将数据块写回磁盘。
Toss-immediate strategy:在处理块的最后一个元组后立即释放该块所占用的空间
Most recently used:系统必须固定当前正在处理的块。 处理完该块的最后一个元组后,该块将被取消固定,并成为最近使用的块
上篇:数据库学习笔记(04): Relational Database Design
下篇:数据库学习笔记(06): Indexing and Hashing
上一篇:
学滑板总摔跤,孩子没信心?快来试试鱼游板,三轮稳定结构,扭腰就能走
下一篇:
最新暴利项目招收代理;一对一指导 全程对接 工资日结
回复
举报
使用道具
分享
返回列表
发新帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
浏览过的版块
后端开发
快速回复
返回顶部
返回列表
 发表于 2023-3-25 15:04:17
|
显示全部楼层
发表于 2023-3-25 15:04:17
|
显示全部楼层