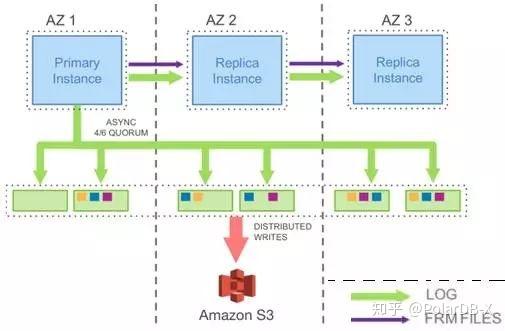
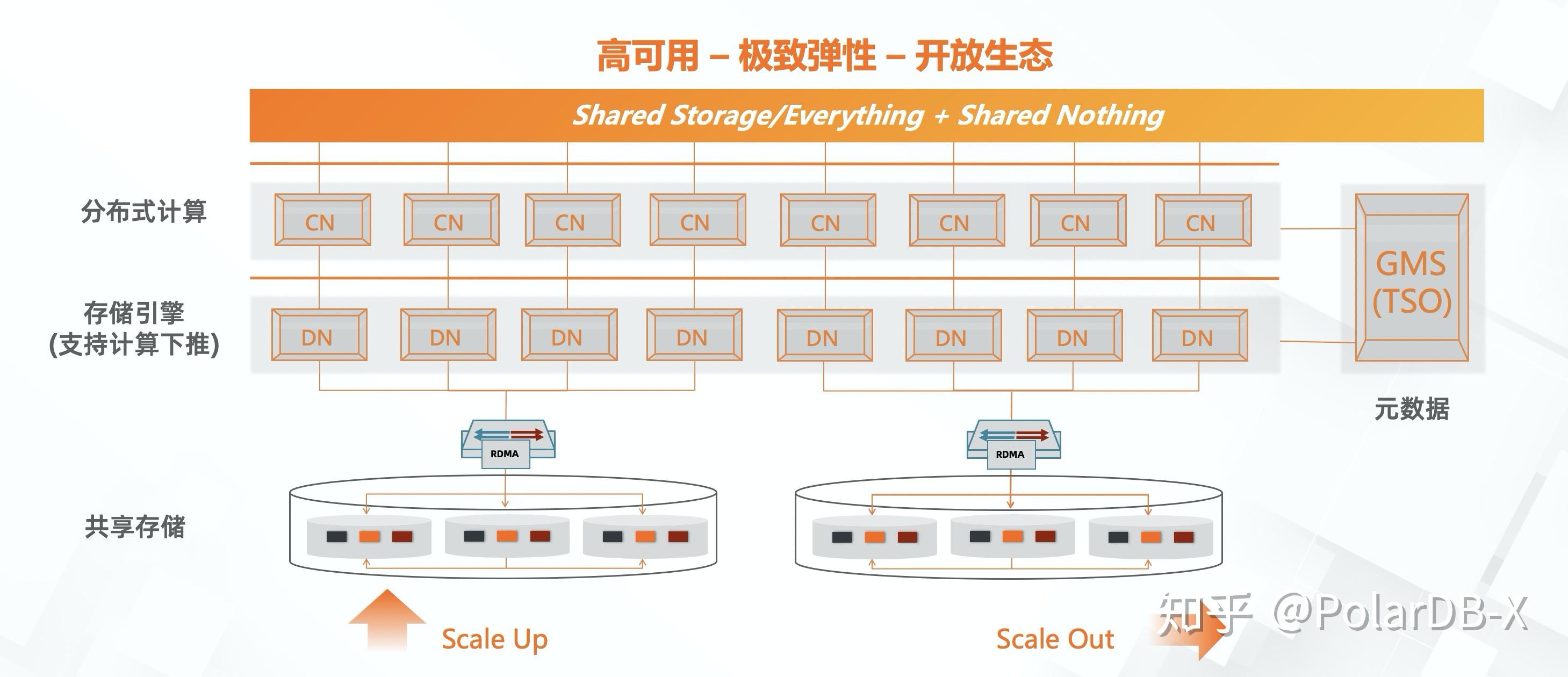
PolarDB 除了共享存储以外还做了许多其他改进,例如锁管理器、buffer pool 等,官方有时会将其称为 shared-everything 架构。
共享存储架构很好的解决了数据库存储容量的 scale out,几乎可以无限扩展。甚至更进一步,云厂商可以将磁盘资源池化,实现按实际使用量付费(pay-as-you-go),大大降低用户使用成本。但该架构也存在明显的瓶颈:尽管存储方面全面拥抱了分布式,但 MySQL Server 这一层还保留着单机数据库的一切,尤其是并发事务处理能力(写入吞吐量),受单个节点的性能上限制约。好在对于大多数用户来说这已经足够了。
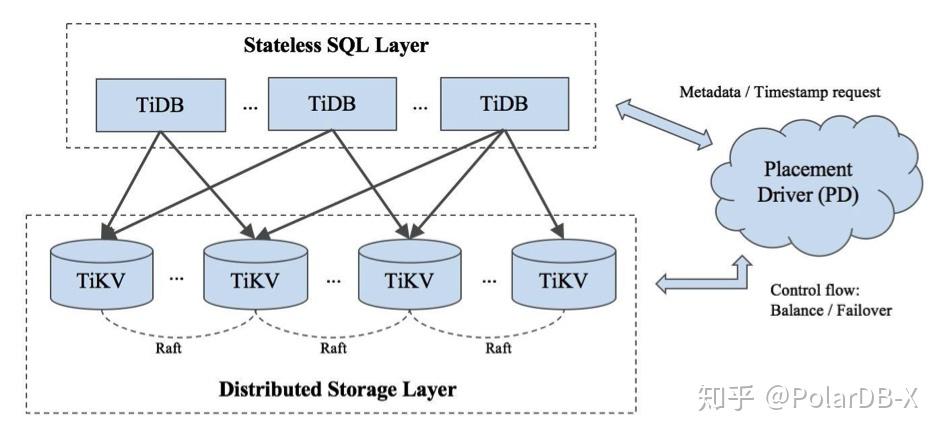
NewSQL 的崛起


 发表于 2023-3-10 13:19:52
发表于 2023-3-10 13:19:52