实现高并发系统是一项系统工程,涉及到数据的全生命周期,从数据入库、更新、查询不一而足,可以说能通过并发来实现加速的地方无所不在——同时还要考虑到系统资源的消耗的问题,要在资源使用与最大化并发之间维系一个微妙的平衡。
随着开源框架、微服务架构、云计算框架的登堂入室,让很多人认为100台机器 x 每台单线程的系统的性能会超越1台机器 x 100线程——确切地说,100台机器的I/O的能力会更强,但是计算能力要弱100倍以上。
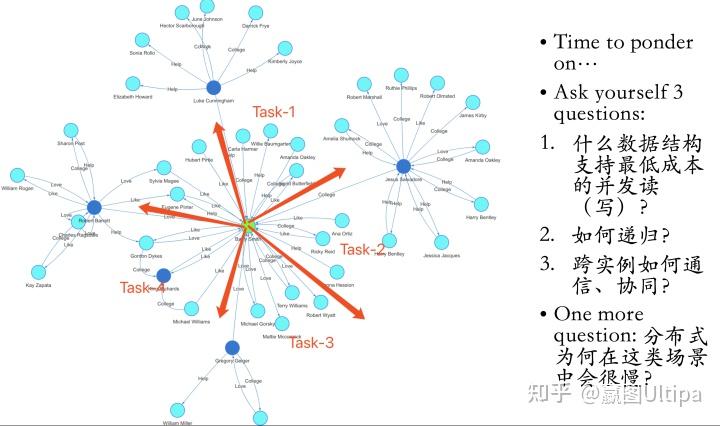
这也是所有BSP(大规模同步处理系统)的难言之隐——会产生这种错误认知的根本原因在于把互联网的短链交易类型的操作与复杂深链查询混为一谈!
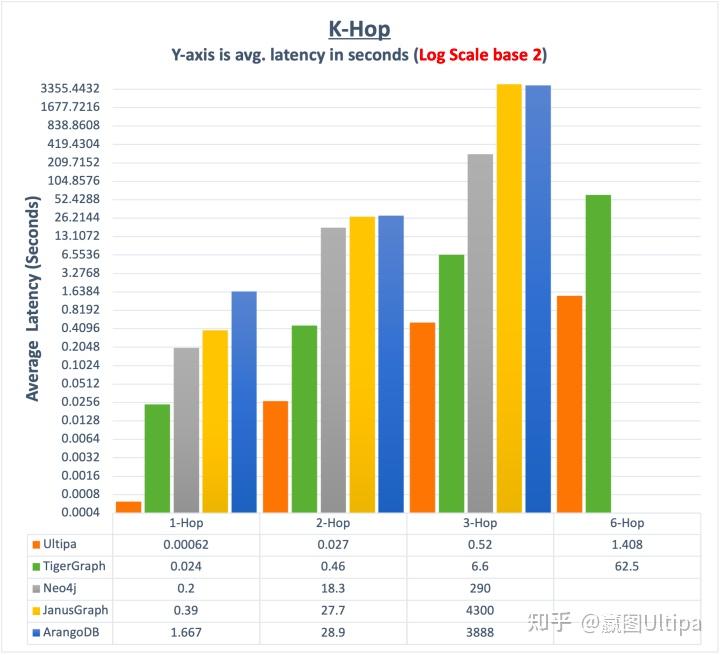
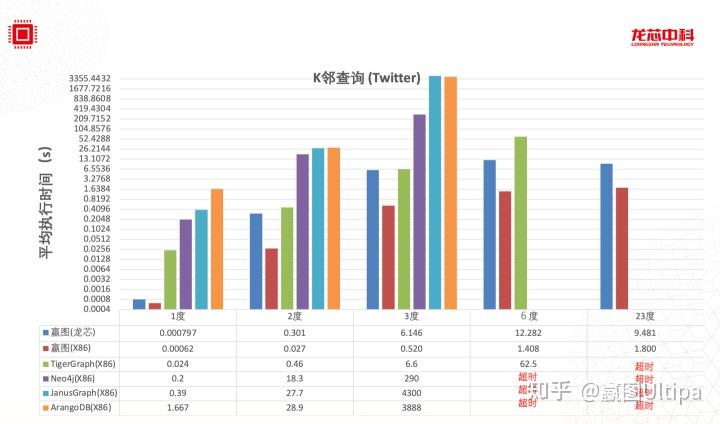
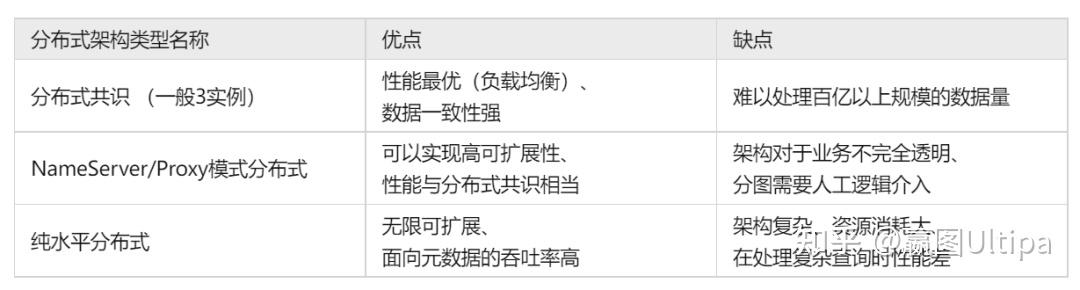
在实操过程中,短链操作可以很好地通过大规模分布式系统架构来实现并发、提速处理,但是对于深链操作,越分布效果越糟糕,因为分布式所造成的多实例间的数据同步、处理等待会比在同一实例上的操作有指数级的性能损耗。
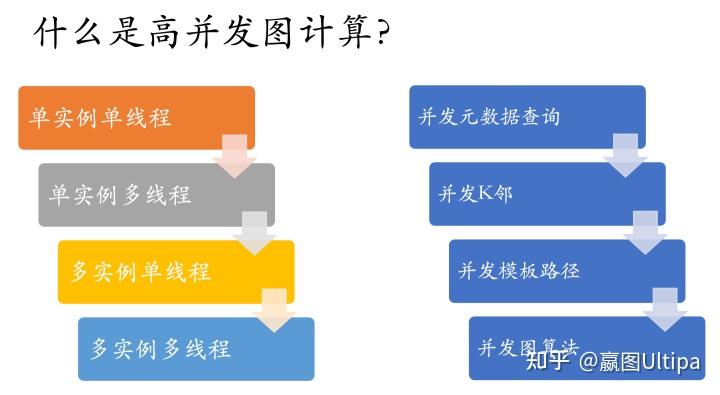
因此,如果我们把所有的图数据库上的操作进行分门别类地剖析,我们可以分为如下几类来分而治之(找到最优、可能且合理的并发加速方式):
元数据与浅层图算法都有比较大的概率可以通过大规模分布式来实现多实例+多线程的加速处理,并能取得很好的效果。而深层图算法与面向高维数据的图查询类操作,集中式的处理(即某个查询在单个实例上,通过多线程并发来处理)会取得更高的吞吐率,这个时候,通过多个实例的来进行负载均衡,可以取得高并发加速的效果(反之,这类复杂查询采用大规模分布式系统来应对就会有事倍而功半的负面效果)。
对于可扩展的分布式系统存在的性能问题,有兴趣延展阅读的可以看一下这篇论文:
Scalability, but at what cost?www.usenix.org/system/files/conference/hotos15/hotos15-paper-mcsherry.pdf


 发表于 2023-1-15 12:08:06
发表于 2023-1-15 12:08:06