|
|
 发表于 2023-1-9 16:36:10
|
显示全部楼层
发表于 2023-1-9 16:36:10
|
显示全部楼层
或许各位或多或少都曾经用过数据库这个玩意,但它对我们而言简直就像个黑箱子——例如,我们可能经常想到下列问题:
- 数据是通过什么格式来存储在内存或硬盘中的?
- 这些数据会在什么时候从内存里移到硬盘中?
- 为什么每一个数据表只能有一个主键?
- 回滚操作是怎么执行的?
- 数据的索引是如何组织的?
- 在什么时候和什么情况下,为了查找一个值需要我们遍历整个表?
- 这些操作语句是通过什么方法存储到内存或硬盘中的?
- ...
以上的问题总结下来就是:一个数据库是怎样工作的?
我们当然可以通过阅读SQLite之类的开源数据库的源码来获取答案,但对于我们而言,或许自己写一个数据库系统出来能够帮助我们更好地理解。这个系统的设计和SQLite很像,但它的特性比MySQL和PostgreSQL之类的还是要少多了,所以我相信大家可以更好地理解数据库的底层原理。另外,整个数据库系统都会被存储在单独一个文件当中,这也减少了大家理解的难度!
SQLite的架构
事实上,SQLite的很多底层细节都已经在他们的官网上打出来了。我们发现下图可以较好地描述SQLite的底层架构:
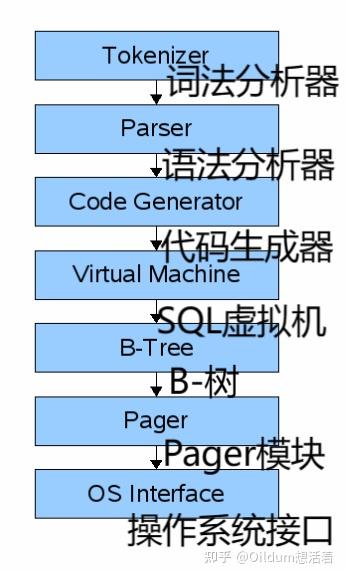
SQLite底层架构图,摘自https://www.sqlite.org/zipvfs/doc/trunk/www/howitworks.wiki
每当SQLite收到一条SQL命令,就会按箭头顺序走一遍上图所示的流程,最终以某种方式获取或修改数据。
我们称它的前端为:词法分析器、语法分析器、代码生成器。
前端整体输入一条SQL命令,输出的则是SQL虚拟机能够辨认的字节码。(译者注:做过编程语言的想必对这一部分非常熟悉吧)
它的后端自然就是:SQL虚拟机、B-树、Pager模块、操作系统接口。这一部分有点复杂,我们拆开来说:
SQL虚拟机的作用就是执行字节码,它实际上的工作是修改或查找对应的索引或表,而它们最终都存储在B-树中。说到底,它的工作就是对B-树进行增删改查,以达到用户所要求的目的。
B-树则是一种数据结构,而它的每一个节点都是以页为单位的。B-树最终的修改都是与磁盘有关(译者注:算法导论里有较具体细节),而在数据库系统中,它的命令不会直接发送到磁盘,而是进入了Pager模块。
Pager模块自然就是操纵具体页所用的结构,它可以接受读或写某一单独页的命令,并且将履行对数据库文件中某特定偏移进行读写的职责。对于最近访问过的页,Pager模块也将把它们缓存在内存当中,同时也决定了在当前时刻,哪些具体页需要写回磁盘。
操作系统接口实质上就是由操作系统提供的一个抽象层,随操作系统本身的改变而改变。SQLite是跨平台的,但本教程中,我们将仅支持Linux平台。
好了,总体而言的结构我们已经了解了。正所谓“千里之行,始于足下”,我们先从最上层的接口——一个简单的REPL开始。
制作一个简单的REPL
如果大家用过SQLite的话就会知道,如果直接运行SQLite的主程序,它将会启动一个REPL,或者说是shell,用于执行SQL命令:
$ sqlite3
SQLite version 3.16.0 2016-11-04 19:09:39
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> create table users (id int, username varchar(255), email varchar(255));
sqlite> .tables
users
sqlite> .exit
$那么下面我们将逐步构建起一个可用的REPL(当然,我们目前只支持 .exit 命令)。先从main()开始:
int main(int argc, char **argv)
{
InputBuffer *input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(0);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}下面我们将按出现顺序依次定义这些结构和函数。
首先,InputBuffer 的定义如下:
typedef struct {
char *buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer; 可以看到,它只是对 char * 的一个小封装。
InputBuffer *new_input_buffer()
{
InputBuffer *input_buffer = (InputBuffer *) malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}new_input_buffer()的作用类似构造函数,初始化了一个最简单的InputBuffer结构并返回。
void print_prompt()
{
printf("db > ");
}print_prompt 用于显示提示符。
下面是最关键的部分:获取输入。我们将使用linux中的库函数 getline,它的调用规范如下:
ssize_t getline(char **lineptr, size_t *n, FILE *stream);如果lineptr所引用的值为NULL,getline还会贴心地帮我们malloc一下。n 则用来存放缓冲区大小,stream则是数据的来源。但这里有一个小细节,getline会把最后的 \n也存到字符串中,我们需要自己把它舍弃掉。
借助 getline,我们将得以实现 read_input:
void read_input(InputBuffer *input_buffer)
{
ssize_t bytes_read = getline(&(input_buffer->buffer), &(input_buffer->length), stdin);
if (bytes_read <= 0) {
printf(&#34;Error reading input\n&#34;);
exit(-1);
}
// Ignore trailing newline
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
} 下面的代码用于回收 input_buffer。
void close_input_buffer(InputBuffer *input_buffer)
{
free(input_buffer->buffer);
free(input_buffer);
}由于在 getline中为 buffer成员分配了内存,所以这里要 free掉。
把它们组合到一起,下面是完整代码:
#include <stdbool.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer()
{
InputBuffer* input_buffer = malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
void print_prompt()
{
printf(&#34;db > &#34;);
}
void read_input(InputBuffer* input_buffer)
{
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf(&#34;Error reading input\n&#34;);
exit(-1);
}
// Ignore trailing newline
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
void close_input_buffer(InputBuffer* input_buffer)
{
free(input_buffer->buffer);
free(input_buffer);
}
int main(int argc, char* argv[])
{
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, &#34;.exit&#34;) == 0) {
close_input_buffer(input_buffer);
exit(0);
} else {
printf(&#34;Unrecognized command &#39;%s&#39;.\n&#34;, input_buffer->buffer);
}
}
}下面是运行结果:
$ ./db
db > help
Unrecognized command &#39;help&#39;.
db > .help
Unrecognized command &#39;.help&#39;.
db > .exit
$恭喜各位,我们已经拥有了一个能用的REPL——虽然功能不多。那么下一篇文章,我们将更新第二部分——数据库系统的前端。 |
|

