立即注册
登录
搜索
前端开发
后端开发
虚幻引擎
U3D引擎
体感研发
数据库
论坛
BBS
本版
帖子
用户
麒麟软控
»
论坛
›
麒麟软控
›
数据库
›
EP36:数据库的种类和使用场景
返回列表
发新帖
EP36:数据库的种类和使用场景
严昌飞
严昌飞
当前离线
积分
13
3
主题
7
帖子
13
积分
新手上路
新手上路, 积分 13, 距离下一级还需 37 积分
新手上路, 积分 13, 距离下一级还需 37 积分
积分
13
发消息
发表于 2023-1-7 17:51:08
|
显示全部楼层
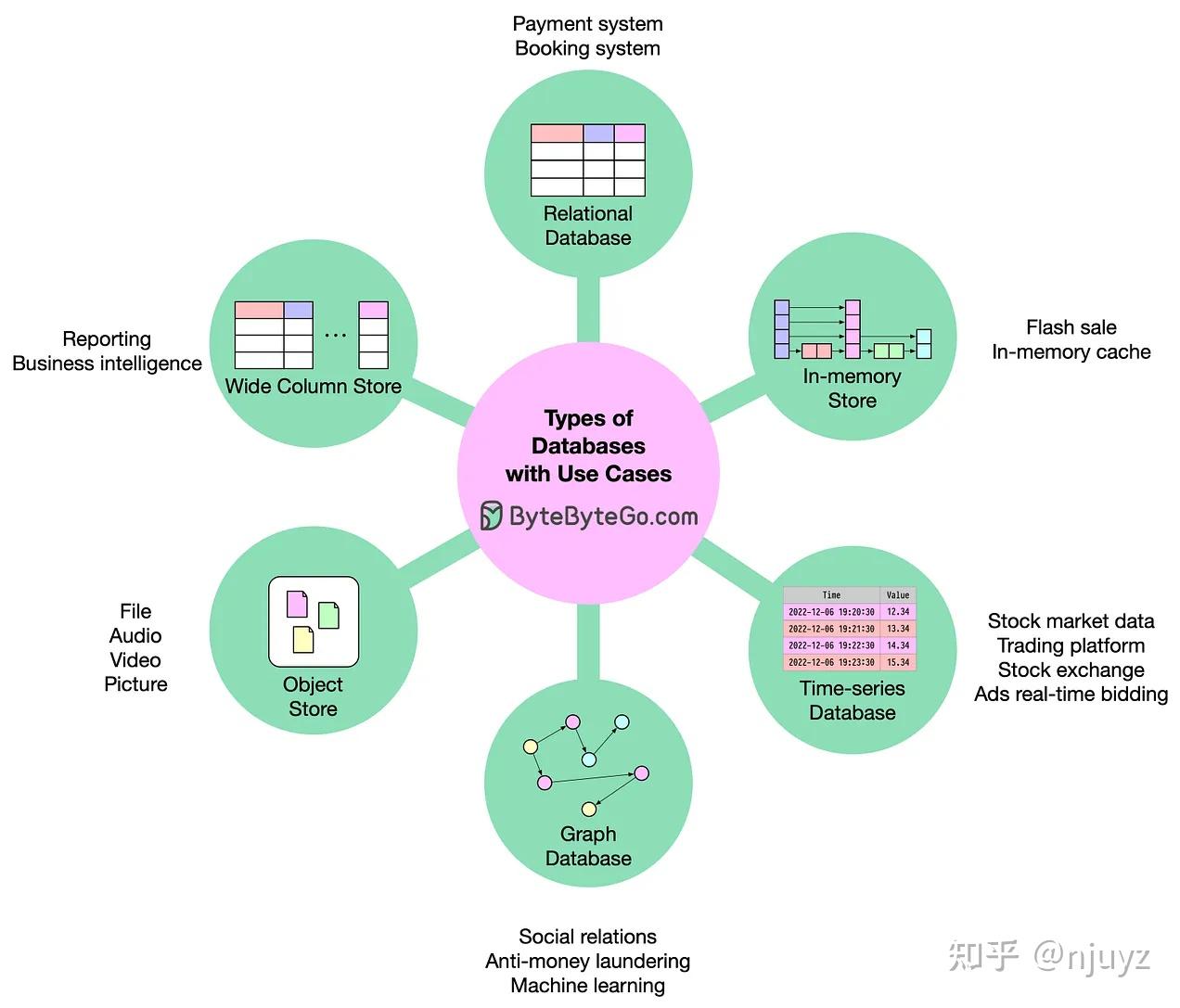
数据库的种类和使用场景
当今的数据库系统成千上万,比如Oracle、MySQL、MariaDB、SQLite、PostgreSQL、Redis、ClickHouse、MongoDB、S3、Ceph等等。你知道如何为你的系统进行选择吗?我做了一个简短的总结。
关系型数据库:几乎可以解决任何类型的问题。
内存数据库:它们的速度和有限的数据容量让它们更适合一些快速的操作。
时序数据库:存储和管理带有时间戳的数据。
图数据库:适合处理非结构化数据之间复杂的关系。
文档存储:适合较大的不变的数据。
宽列存储:常用于大数据、分析、报表等场景,处理非正规化数据。
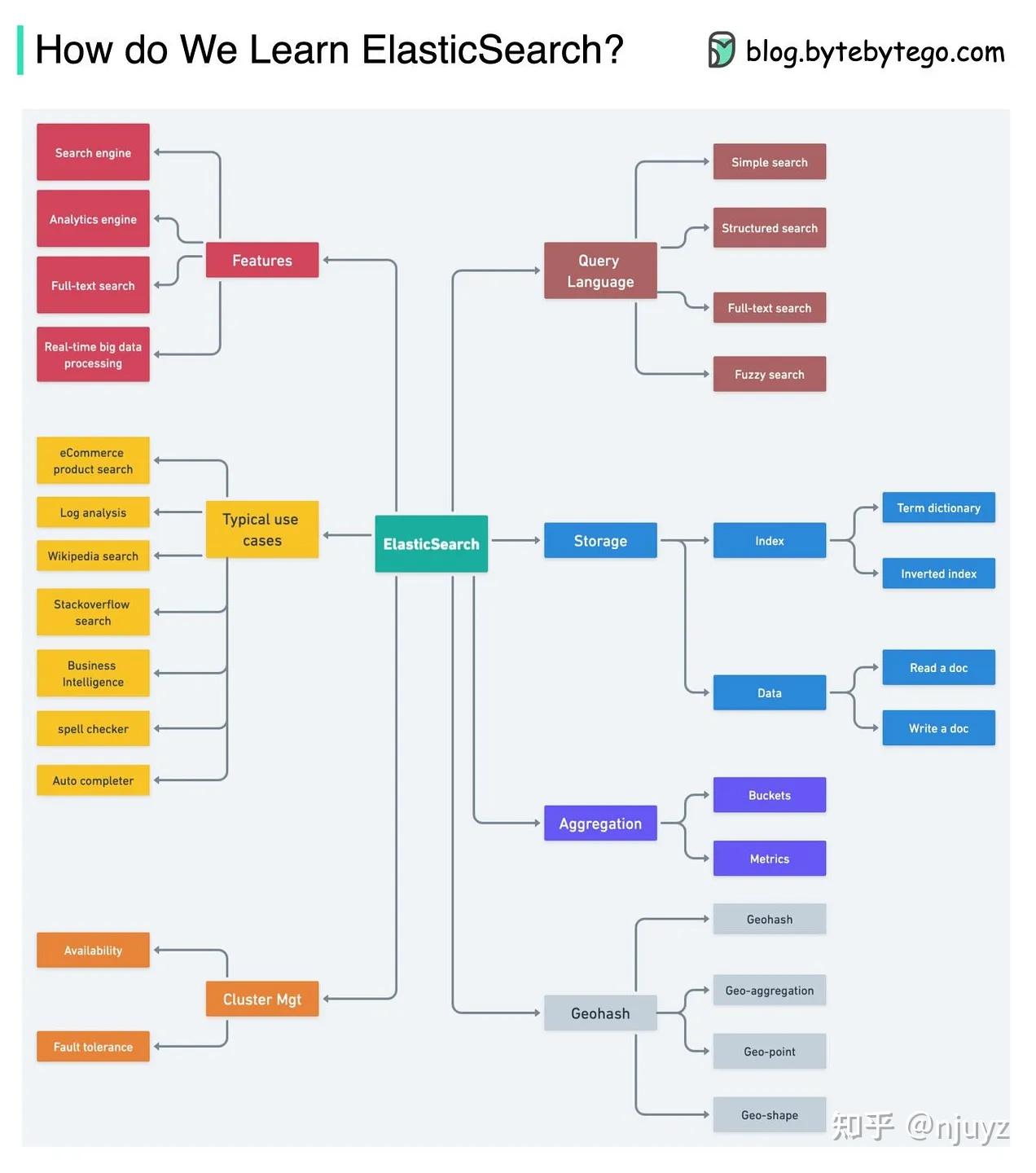
如何学习ElasticSearch
ElasticSearch基于Lucene库提供搜索功能。它提供了一个分布式、多租户的全文搜索引擎,并附带HTTP的接口和非结构化的JSON文档存储。下图展示了一些概要。
ElasticSearch的特性:
实时全文检索
分析引擎
分布式Lucene
ElasticSearch的使用场景:
电商网站中的上品搜索
日志分析
输入自动补全,拼写检查
商业智能分析
维基百科的全文检索
StackOverflow的全文检索
ElasticSearch的核心是数据结构和索引,重点要理解ES使用LSM树(日志结构和合并树)来构建短语词典。
给你的问题:你有没有在项目中用过ElasticSearch,用在什么地方呢?
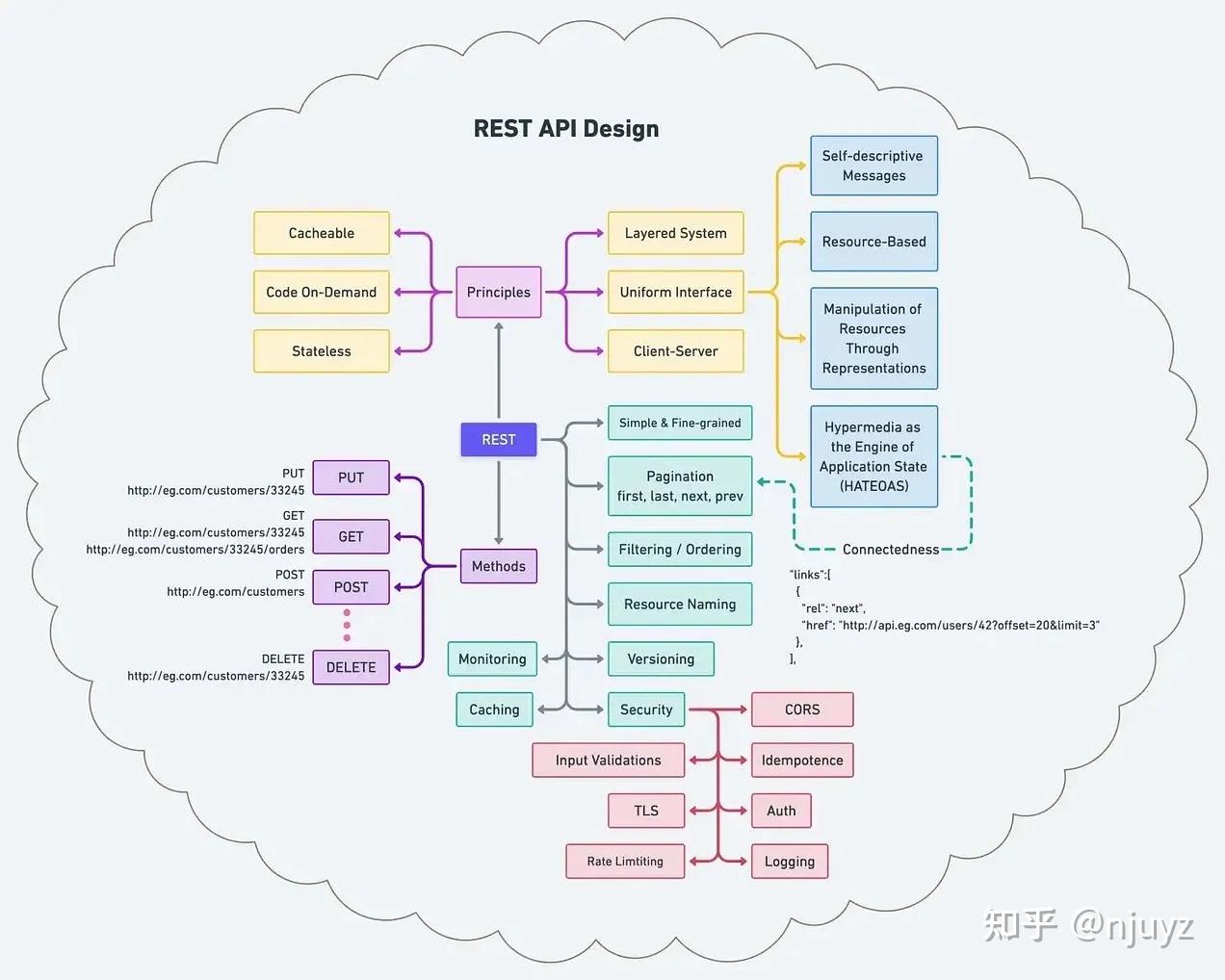
REST API的设计
REST API有哪些原则、方法、限制和最佳实践?我希望下图可以给你一个快速的概览。
分享来自Love Sharma的文章,原文地址。
本文的读者是想要打造跨服务、高可靠、一致性RESTful服务的开发者。下面这些原则指导了内外部的服务开发,我们对图中的要点逐一展开来说。
六大原则和限制
客户端-服务端
:关注分离是CS限制的背后原则。通过将用户界面的关注从数据存储分离出来,我们可以改善用户界面的跨平台可迁移性;通过简化服务端组件,可以改善扩展性。
无状态
:通信必须是无状态的,也就是“客户端-无状态-服务端“(CSS)风格。每个来自客户端的请求必须包含所有理解请求所必须的信息。因此会话状态完全保存在客户端。
可缓存
:为了改善网络效率,我们增加了缓存限制,形成了”客户端-缓存-无状态-服务端“风格。缓存原则要求响应请求的数据都应该隐式或者显式地标记自己是可缓存或者不可缓存的。如果一个响应是可缓存的,那么客户端缓存应该有权将响应数据重用于后续的等价的请求。
分层系统
:客户端应该无法分辨其是直接连接的后端服务器还是中间的某个节点。中间服务器通过负载均衡和共享缓存,可以提升系统的可扩展性。分层还可以强化安全策略。
按需编程
:REST可以通过下载和执行applets和脚本类型的代码来扩展客户端功能。通过减少需要预先实现的特征数量来简化客户端。它让系统特性可以在部署之后再下载,改善了系统的扩展性。
统一接口
:通过将软件工程的原则应用于组件界面,系统的整体架构变得简洁,交互的可见性也得到改善。实现和服务接口解耦,使其可以独立进化。通过四个限制条件来定义REST:资源的标识、通过表现层来操作资源、自描述的消息和作为应用引擎状态的超媒体。下面详述:
自描述消息
:每个消息都应该包含足够的信息来描述如何处理消息。
基于资源
:请求中的各个资源通过URI这个资源标识符来标记。资源本身在概念上有别于返回给客户端的表现内容。
通过表现层操作资源
:当客户端表现一个资源,包括任何附带的元数据,它就有了足够的信息来修改或者删除服务器上对应的资源,当然,需要有权限。
将超媒体作为应用状态的引擎(HATEOAS)
:客户端通过body内容、查询参数、请求头和请求的资源名来提交状态。服务通过body内容、响应代码、响应头来提供状态给客户端。
最佳实践
接下来让我们转向REST的基本最佳实践,这也是每个工程师应该知道的。
保持简单和细粒度
:创建的API应该模拟你系统底层的应用领域或者数据库架构。最终你会要聚合服务,一种调用了多个底层资源的服务,以减少交互。
过滤和排序
:对于大型数据集,出于带宽的考虑,限制返回的数据量是十分关键的。此外我们可能还要指定哪些字段或属性应该包含在响应结果中,以实现对返回数据量的限制。最终我们只需要查询特定的值并对返回数据进行排序。
版本化
:在API开发中有许多做法会破坏契约并对客户端造成负面影响。如果你不确定你的修改有多大的影响,最好小心形式并对其版本化。当我们考虑是做一个新版本还是修改现有的版本时,有许多因素需要考虑。鉴于维护多个版本的代价大、复杂、易错,你对任何资源都不应该维护超过两个版本。
缓存
:缓存通过在分层系统中减少远程调用来提高可扩展性。服务通过设置响应头中的字段,比如Cache-Control、Expires、Pragma、Last-Modified等来优化可缓存性。
分页
:REST的原则之一是连通性,通过超媒体链接来做。同时,没有它们的时候服务仍然是有用的。 在响应中包含链接使得API更加具有自描述性。对于响应中返回的支持分页的数据集合,至少包含”第一“、”最后一个“、”下一个、“前一个”的链接是有帮助的。
资源命名
:当资源命名合理的时候,API是符合直觉并易于使用的。反之,同样的API就会让人迷惑,难于使用和理解。RESTful API是用消费者服务的。URL的命名和结构应该对消费者传递含义。人们通常很难知道数据边界在哪里。但是一旦理解了你的数据,你立马就能出手,知道应该给客户端返回什么数据是有意义的。为你的客户端设计,而不是你的数据。
复数
:一个普遍接受的原则是把复数用于节点的命名,以保持API的URI在所有的HTTP方法中保持一致。其理由在于,“customers”是服务中的一个集合,而ID(比如33245)指向集合中的某一个实例。
监控
:确保增加各类监控来提升你的API的质量和性能。具体的数据点可以是响应时间(p50, p90, p99),状态代码(5XX,4XX等),网络带宽,等等。
安全
:
认证和鉴权
:认证和鉴权是一样的。问这个问题“这个主体有没有权限来请求给定的资源”
跨域
:实现跨域只要添加一个额外的HTTP响应头,比如Access-Control-Allow-Origin,Access-Control-Allow-Credentials等。
TLS
:所有的身份认证都应该使用TLS。OAuth2认证服务器和访问token使用TLS。
幂等
:一个操作执行一次或多次应该是一样的结果。基于上下文不同,可能有不同的涵义。比如在包含副作用的调用或子函数中,它意味着修改后的状态在第一次调用之后就保持不变。
输入校验
:校验所有输入到服务器的内容。接受好的输入,拒绝坏的输入,抵御SQL和NoSQL注入,限制消息尺寸不超过字段大小,服务只展示通用的错误信息,等等。
限流
:这是限制网络流量的一种策略。它对某人在某个时间段内可以重复多少操作设置了上限。比如,尝试登陆某个账户。
日志
:确保你不会意外记录任何个人隐私信息。
通过我总结的这些经验,希望能帮助读者学到一些,也请和同事朋友分享,谢谢。
上一篇:
数据库事务概念和实现技术
下一篇:
“数据库内核从入门到精通 ”系列课开讲!
回复
举报
使用道具
分享
返回列表
发新帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
快速回复
返回顶部
返回列表


 发表于 2023-1-7 17:51:08
发表于 2023-1-7 17:51:08