|
|
 发表于 2023-4-4 14:30:36
|
显示全部楼层
发表于 2023-4-4 14:30:36
|
显示全部楼层
在数据库领域,Snowflake和Redshift等知名数据仓库产品的崛起引发了业界的高度关注。近年来,实时数据库和流数据库成为了数据库领域两个备受瞩目的类别。实时数据库方面,Apache Druid、Apache Pinot、Apache Doris和ClickHouse都是近期崭露头角的优秀产品;流数据库方面,KsqlDB、RisingWave和Materialize也是近年来涌现出来的代表系统。作为数据库领域的实践者,我经常听到有关实时数据库和流数据库异同的讨论。这些讨论是理所当然的,因为这两类产品看似都具备分析功能,都在朝着“实时”这个方向发展,也都提供存储、物化视图和随机查询等功能。随着"流批一体"、"实时数仓"与”流式数仓“等概念的出现,人们对这些产品的异同感到更加困惑。本文将从实践角度探讨这些产品之间的关系、现有格局的形成以及未来的发展趋势。
技术栈的演进
实时计算引擎与流处理引擎分别被引入到技术栈中,为用户提供实时计算能力的支持。实时计算引擎解决了对用户查询进行低延迟响应的需求;流处理引擎解决了用户对结果新鲜度的需求。
让我们穿越回十年前,那个大数据技术正在逐步兴起的年代。在当时,企业中的数据量正高速增长,不少公司都需要搭建自己的数据中心来满足对数据的管理与分析的需求。一个最典型的数据中心技术栈如下图所示。
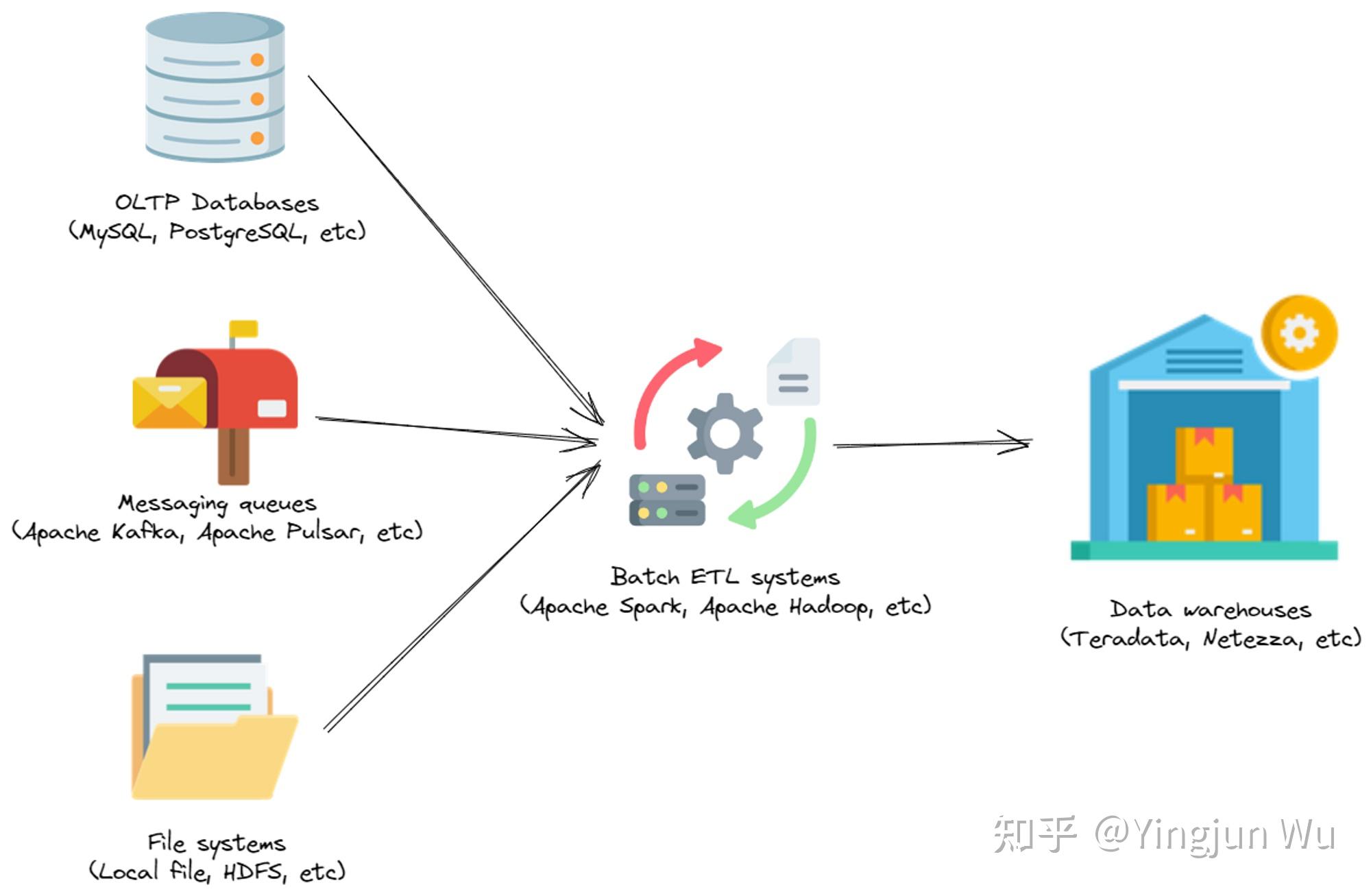
十年前的企业内部技术栈。
用户数据通过多种途径,例如OLTP数据库(如MySQL、PostgreSQL)、消息系统(如Apache Kafka、Apache Pulsar)、文件系统(如本地文件、HDFS)等进行采集。然后,ETL系统每天从这些数据源中拉取数据,经过批量处理后导入到数据仓库中。当企业内部用户需要对历史记录进行分析时,他们会连接到数据仓库,执行大规模数据处理。
这样的技术栈对于当时的多数场景来说还是足够的。但随着移动互联网的兴起,科技企业对数据的需求不断变化。在Uber、LinkedIn等公司内部,数据呈爆炸式增长,对数据分析的要求也更加实时化。传统的批量ETL导入数据仓库、并在数据仓库进行查询的方式已经不再适用了。为什么呢?主要是有两个核心问题:第一,数据仓库由于往往需要对数据进行全局扫描才能完成数据分析,从用户发出信息到用户获得结果需要很长的时间;第二,批量导入的方式使得数据从进入消息源到可以被查询(queryable)的延迟很高。
第一个问题导致的直接影响是数据仓库无法顺利支持交互式报表查询。人类的思维方式往往是多变且发散的。在使用交互式报表时,用户很可能会连续地进行多次随机查询,以获得不同维度的分析结果。然而,当数据仓库响应缓慢,需要较长时间才能返回查询结果时,用户就会面临系统流畅度不佳的问题,这无疑会影响用户的分析体验和工作效率。实时计算引擎的诞生便是为了解决这一问题。其使用诸多技术,例如对数据分片、向量化处理、预聚合、构建索引等方式,保证可以在极低延迟内便返回给用户结果。如此一来,用户便可以在报表系统中自由的高效的对大量数据进行顺畅的查询,实现了体验的飞跃。
第二个问题直接造成用户无法根据最新结果做出决策。在企业中,根据实时结果做出实时决策可能能够大幅提升利润、降低成本。在股票交易、库存管理、资源监控等方面,当用户看到的是一天之前的结果而并非一分钟之前的结果时,做出的决策往往会有很大偏差。为了解决这一问题,流处理引擎便诞生了。大数据时代的流处理引擎,如Apache Storm、Apache Samza、Apache Flink等等,被用来进行实时ETL。只要当上游有数据进入,便会触发流处理引擎进行计算,等计算完之后便直接插入到数据仓库中,使得用户的数据可以在很短的时间内(秒级或者分钟级)便可以被用户查询到。在一些场景中(例如欺诈检测、报警等),用户希望对某些查询结果实时进行监控。为了实现这一需求,用户会将流处理引擎所产生的计算结果直接导出到一些存储系统中,并在那里实现对结果的高并发访问。
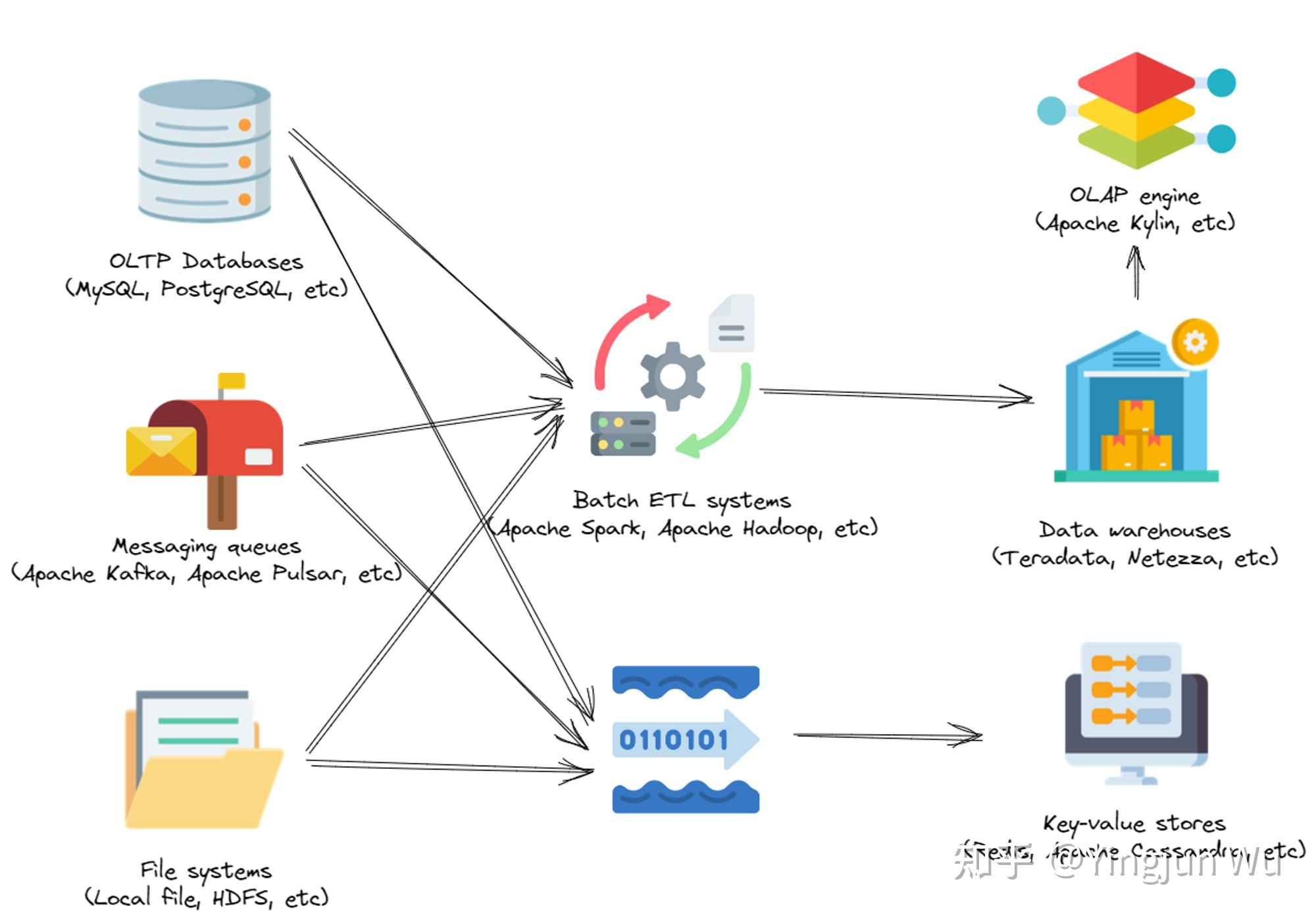
实时计算引擎与流处理引擎被引入到企业技术栈中。
随着企业对数据处理能力要求的进一步提高,内部的技术栈也越发变得复杂。上图简单描述了逐渐演变的企业技术栈。实时计算引擎与流处理引擎的引入可以更好的满足企业对实时的需求。
从引擎到数据库
实时计算引擎与流处理引擎为了提升性能、易用性与正确性,逐步演进成实时数据库与流数据库。
在过去的十年里,数据处理系统经历了深刻的变革,系统设计发生了巨大的改变。其中,实时计算引擎和流处理引擎这两类系统逐步演进成为实时数据库和流数据库。例如,最早期的Apache Druid、Apache Pinot与ClickHouse这些产品最早主要用来加速报表查询,而如今都已经成为独立的具有存储能力的实时数据库。在流处理引擎中,Apache Flink也正在开发自己的存储系统Apache Flink Table Store来补充自己在存储方面的能力。为什么在这两个领域中,大家纷纷从“引擎”转向“数据库”?难道是一种巧合?实际上,这种转变带来的是对系统性能、易用性与正确性的大幅提升。
引擎作为计算组件,往往不直接持久化数据,这导致了多个问题。首先,频繁访问外部数据源会造成巨大的性能开销,影响计算性能;其次,用户只能使用引擎进行计算,需要以来其他系统访问计算结果,增加了复杂性和操作不便;再者,每个系统有着自己独立的正确性保证机制,而当计算流程牵扯到访问多个系统获取数据时,计算结果的正确性无法得到整体保证。因此,这两类引擎都迈向了数据库化的发展道路,以解决上述问题。下面我们将详细介绍这一演进过程。
从实时计算引擎到实时数据库
实时计算引擎的初衷是加速用户的分析型查询,实现低延迟的响应。最初,这类引擎需要从数据仓库中不断抽取数据,为数据仓库中的数据构建索引与物化视图以加速查询。然而,这种做法存在局限性:无法获取实时产生的最新数据;对于一些复杂查询仍需回到数据仓库进行处理;计算产生的结果可能出现一致性问题。
实时计算引擎向实时数据库的演进对这些问题给出了答案。实时数据库不仅能够存储数据,并且能够直接从数据源中摄入数据。这意味着用户可以实时访问到最新的数据,同时实现高效的分析查询。实时数据库的出现极大地提升了查询性能,同时简化了用户的操作流程。
从流处理引擎到流数据库
流处理引擎的主要作用在于实时处理数据流,并将处理结果导入下游的存储系统供用户访问。然而,这种架构存在较高的复杂性,同时用户希望能够将最新产生的数据与历史数据进行综合分析,这使得对外部数据源的访问变得不可避免。
为了简化架构并提升性能,流处理引擎逐渐演进为流数据库。流数据库不仅能够实时处理数据流,还能对数据进行持久化存储,从而实现对实时数据和历史数据的一体化查询和分析。流数据库的出现使得用户可以直接在一个统一的系统中进行实时查询和分析,极大地提升了数据处理效率,并降低了用户的操作复杂性。
实时数据库与流数据库的异同
实时数据库侧重于对用户随机发起的查询进行低延迟响应;流数据库侧重于对预定义计算低延迟生成计算结果。
正如一开始所提到,实时数据库与流数据库解决的问题有一定的重叠,而从技术角度也拥有颇多相似之处:两者都能存储数据,都提供物化视图,都能支持随机查询。那么这两类数据库有何异同呢?
从目前来看,实时数据库与流数据库所处理的场景还是有较大差异。实时数据库与流数据库都被人们认为是能够支持实时分析。而实时数据库的侧重点在于提供交互的实时性,流数据库的侧重点则在于提供结果的实时性。也就是说,实时数据库可以低延迟的处理用户随机发起的查询,因此其更经常的被利用在交互式报表等领域。相比之下,流数据库可以更好的支持预定义的查询,一旦新的数据流入,流数据库便利用增量计算的方式更新查询结果,因此其更经常地被利用在了报警、监控等领域。相比于实时数据库,流数据库继承了流处理引擎支持实时ETL的能力,也就是说,流数据库能够将多个消息源的数据进行加工处理之后导出到下游数据系统中。
实时数据库与流数据库在技术上看似有很大重叠,但按目前的发展进度来看,仍然有不少区别。尽管实时数据库与流数据库都能够提供物化视图功能,但实时数据库的物化视图主要被用于加速随机查询,而流数据库的物化视图主要是为了定义计算以及保存结果。进阶的流数据库系统一般都会实现窗口运算、精确一次性(exactly once)、乱序处理(out-of-order processing)等功能,而这些功能尚未被实时数据库所支持,因此用户并无法使用实时数据库做进阶的流处理。实时数据库与流数据库也都支持随即查询功能。实时数据库使用列式存储、向量化计算等方式对原始数据进行高速查询。然而,流数据库更多优化的是对计算结果的单点查询,现有的流数据库暂未实现列式存储,这也意味着流数据库暂时无法像实时数据库那样进行高效全局扫描查询。
流批一体、实时数仓与流式数仓
实时数据库与流数据库从技术角度趋于统一,并逐步向数据仓库演进。但技术发展仍需要数年时间,短期内仍是互利共存状态。
近年来,"流批一体"已成为数据库领域的热门话题。许多人主张使用同一系统将流处理与批处理统一起来。实际上,这是对实时数据库与流数据库融合的宣传。因为在目前的情况下,实时数据库主要关注全量计算,而流数据库则侧重于增量计算。将这两种计算方式融合起来似乎能显著简化企业内部的技术架构。我认为这种融合是完全可行的,因为从系统设计的角度来看,实时数据库与流数据库之间并不存在无法解决的矛盾。将两者融合的最大挑战在于工程复杂性。开发出一套稳定且高性能的流批一体系统可能需要3到5年的时间。当然,这仅是我从技术角度的分析结论,一个产品能否被大规模接受还需经市场验证。我认为,在接下来的几年里,实时数据库与流数据库将相互补充而非简单替代。
另外,在数据库领域还有两个流行词汇:“实时数仓”与“流式数仓”。显然,人们期待实时数据库与流数据库能进一步从“数据库”演化为“数据仓库”。这种想法是合理的,因为当系统具备存储数据的能力时,为何不尝试成为企业数据架构中的真实数据来源(source-of-truth)呢?然而,目前实时数据库与流数据库距离数据仓库的标准仍有一定差距。原因在于,实时数据库与流数据库的优化重点在于计算能力,而数据仓库更注重存储能力的优化。这也是为什么我们看到现有的数据仓库正逐渐走向“湖仓一体”(lakehouse)范式的原因。
总结
实时数据库与流数据库是近年来数据库领域的两大热点。相信在接下来的两三年中,这两个类别会持续高速发展,并出现竞争。当然了,无论技术如何先进,要成为好的商业化产品,最后还是需要获得市场的接受。在商业化过程中,技术其实只占了很小的比重。因此,无论我们怎么从技术角度分析与判断,在商业化方面出现任何结果都不会让我感到意外。希望有更多开发者关注与使用这两类技术,并提出宝贵的意见!
<hr/>广告时间:RisingWave是一个分布式SQL流数据库。相比于其他流处理系统,RisingWave专注于为开发者提供更好的易用性、更高的性价比、以及强一致性。RisingWave开源版本(Apache 2.0协议)已经达到生产就绪状态,欢迎各位使用!
添加微信小助手加入RisingWave中文社区用户交流群:risingwave_assistant |
|

