立即注册
登录
搜索
前端开发
后端开发
虚幻引擎
U3D引擎
体感研发
数据库
论坛
BBS
本版
帖子
用户
麒麟软控
»
论坛
›
麒麟软控
›
数据库
›
数据库学习笔记(07): Query Processing
返回列表
发新帖
数据库学习笔记(07): Query Processing
阳光下的宅女
阳光下的宅女
当前离线
积分
11
3
主题
5
帖子
11
积分
新手上路
新手上路, 积分 11, 距离下一级还需 39 积分
新手上路, 积分 11, 距离下一级还需 39 积分
积分
11
发消息
发表于 2023-3-25 20:14:31
|
显示全部楼层
SQL非过程式,关系代数过程式
Measures of Query Cost
查询代价
可以通过该查询对各种资源的使用情况来度量,如磁盘访问、CPU时间(实时系统会考虑),甚至网络传输时间(分布式数据库会考虑网络因素)。通常在大型数据库系统中,
磁盘访问时间
是最主要的代价,决定整个查询的时间,且容易估计。具体分析以下因素:
查找次数(寻道的数量)×平均查找时间
读数据块的个数×平均读数据块的代价
写数据块的个数×平均写数据块的代价
通过将磁盘读和磁盘写区分开,可以细化磁盘存存取的代价估算。因为写磁盘块的代价是读磁盘块的代价的2倍,原因是
写完之后要重新读
以验证写操作已完成。
t_T :传输一个数据块的时间
t_S :磁盘平均访问时间(搜索+旋转)
b*t_T+S*t_S 表示b个数据块执行S次磁盘搜索的时间
Selection
A1
线性搜索
:系统扫描每一个文件块,对其中的记录进行检查是否满足选择条件
查询代价
(b_r是关系r中record一共的存储块数)
b_r * t_T + t_S 。花费一次访问定位找到头部,顺序读完所有块
如果是对key属性进行判断(唯一的key),平均查询代价是 (b_r)/2 * t_T + t_S
最基础,最慢,任何条件都可以
A1'
二分
查询
条件
:属性等值比较且有序
代价
:
\lceil log_2 (b_r) * (t_T + t_S ) \rceil
查找时不连续,每一次都需要传输和定位
A2
A2~A6
索引
扫描:应用索引的查找算法,查找条件必须是
index的search-key
上的比较
主索引
,
key
上等值比较
代价
:
h_i * ( t_T + t_S) + (t_T + t_S)即 (h_i+1) * ( t_T + t_S)
hi是B+树的高度,前面是访问索引文件的代价,后面是访问数据块的代价
create index on ID select * from instructor where ID=22222
A3
主索引
,在
非key
属性上等值比较
代价
:
h_i * (t_T+t_S) + t_S + t_T*b
数据文件的访问有一次seek和b次传输,因为非key属性查询返回多个记录,这些记录连续存储
create index on dept_name select * from instructor where dept_name = 'Comp.Sci'
A4
辅助索引
,等值查询
代价
:
如果search-key是
candidate key
: (h_i +1) * (t_T + t_S)
查询返回一条记录
如果search-key不是candidate key: (h_i + n) * (t_T + t_S)
查询返回多条记录且这些记录不连续,每一块都需要seek和传输
create index on salary select * from instructor where salary=80000
A5
主索引
,
比较
对于查询 \sigma_{A\geq V}(r) ,用index查找到 A \ge V 的第一个记录后顺序扫描文件
对于 \sigma_{A\leq V}(r) ,不需要访问index文件,只需从
文件头开始
扫描直到 A> V 的记录出现
A6
辅助索引
,
比较
对于查询 \sigma_{A\geq V}(r) ,index查找到 A \ge V 的第一个记录后顺序访问索引文件,通过索引记录的指针找到数据记录
对于 \sigma_{A\leq V}(r) ,只需访问索引的叶子节点,通过可一个K的指针找到数据记录直到第一个 A>V ,查询结束
连续的记录可能存储在不连续的存储块中,找到每一个数据记录都需要一次I/O,代价比直接线性扫描数据文件的代价还要大。因此,辅助索引只有在找到的
记录数目很小
时使用
A7
A7~A9 Conjunction ^
应用索引的合取选择
首先判断是否存某个简单条件中的某个属性上的存储路径,若存在,则选择A2~A6之一的算法检索满足该条件的记录,然后再
内存缓冲区中测试
检索到的每一个记录是否满足其余的条件
A8
应用多值索引的合取选择
在多个属性上建立的一个索引
A9
通过标识符的交运算实现合取
查询条件涉及到的属性上要求有索引,利用这个索引查找满足相应条件的记录的指针,进行
交集
,然后找到相应的数据记录
A10
通过标识符的并运算实现析取disjunction V
如果所有的析取选择条件上
均有索引
,利用这个索引查找满足相应条件的记录的指针,进行
并集
,然后找到相应的数据记录
否则线性扫描
Negation
\sigma_{\lnot \theta} (r) 线性扫描
如果满足的record很少且\theta适用索引,则使用索引
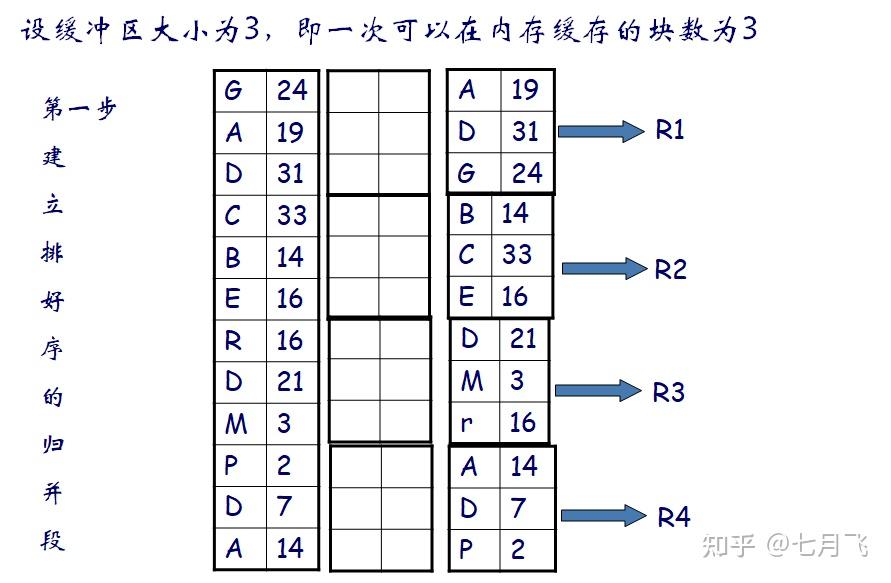
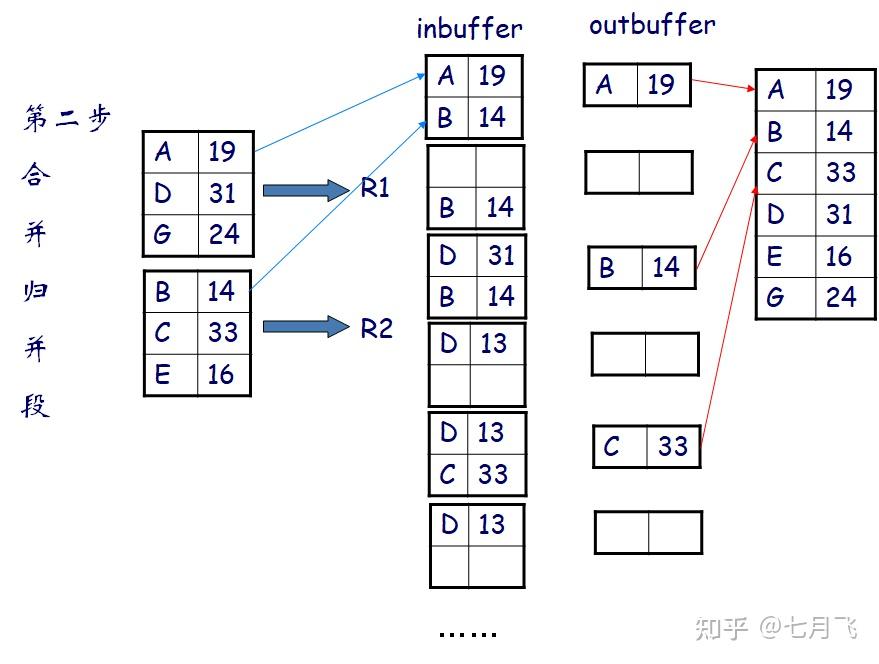
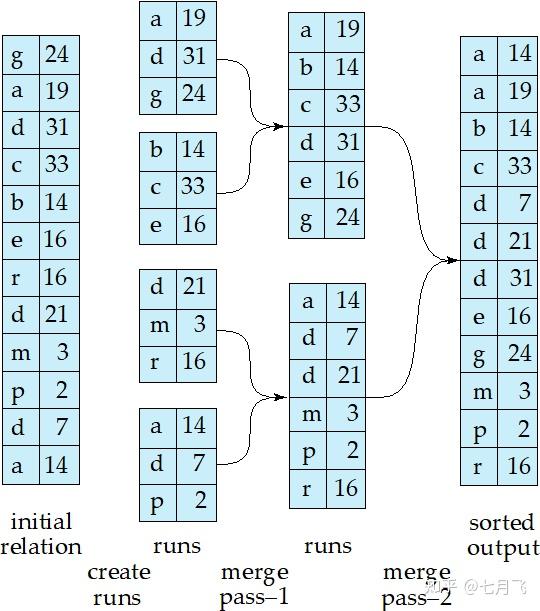
Sorting (External sort-merge)
内存缓冲区能容纳
M
页,一次可以读取的块数M
第一阶段
创建归并段
runs
从数据文件中读M个块到内存
在内存中对读入的额数据进行排序;
排好序的数据写回到归并文件Ri中
i=i+1
最后得到N个归并好的文件R,N是最后循环的次数i
N-way merge:N个缓冲块输入归并文件,一块缓存输出。将每个归并段的第一块读入各自的缓冲区
归并阶段
:循环完成以下工作,直到输入缓冲区中的buffer页为空。
从所有的buffer页中有序选出第一个记录(基于内存的归并排序的思想)
将该记录写到输出buffer,并从input buffer中删除这个记录;如果输出buffer满了将其中的数据记录写到磁盘;
如果任何一个归并段Ri对应的buffer页空了并且没有到达Ri文件的末尾,则读入Ri的下一块到对应的input buffer中
代价
b_r 表示关系r中记录一共占用的
存储块
数
在
建立
排好序的归并段Ri阶段,要读入关系(待排序的关系表)的每一个块并写出,因此每一趟块
传输
为 b_r + b_r = 2 b_r
在
归并阶段
传输的数据块数与归并的
趟数
有关。每一趟归并,归并段数减少为上一次的 1/(M-1) ,因此归并的趟数为 \lceil log_{M-1} (b_r / M) \rceil
忽略最后一次写操作。加上建立R阶段的代价,
总传输块数
为 2b_r\lceil log_{M-1} (b_r / M) \rceil + b_r
在
建立
排好序的归并段Ri阶段,读取每个归并段都需要seek,写回磁盘也需要seek,一共 b_r/M 个归并段。因此,这个阶段的seek代价为 2\lceil b_r / M \rceil
在
归并阶段
,设b_b是一次从归并段读取到内存的块数,则每次归并需要做 \lceil b_r / b_b \rceil 次seek来读数据,写回磁盘又需要 \lceil b_r / b_b \rceil 次seek,一共趟归并 \lceil log_{M-1} (b_r / M) \rceil ,则需要 2\lceil b_r / b_b \rceil \times\lceil log_{M-1} (b_r / M) \rceil 次seek。但是,最后一趟只需要读数据块的seek,忽略写回磁盘。因此这个阶段的seek代价为 2\lceil b_r / b_b \rceil \times\lceil log_{M-1} (b_r / M) \rceil - \lceil b_r / b_b \rceil
两次seek相加得到 2\lceil b_r / M \rceil +\lceil b_r / b_b \rceil (2\lceil log_{M-1} (b_r / M) \rceil-1)
Join
重点介绍Nested-Loop join & Block Nested-loop join
Nested-loop join
n_r 是外关系的记录数, n_s 是内关系的
最坏情况下,如果内存仅能容纳每个关系的一个数据块
传输块数
为 b_r + n_r * b_s 。其中 b_r 表示关系r的每一个数据块都需要读, n_r*b_s 表示对于关系 r 的每一个记录,都要读关系s的每个数据块
,
做匹配计算,共 n_r 次
Seek次数
b_r+n_r ,其中关系r的每一个块都需要seek,需要 b_r 次(读完r的第一块后,块中每条记录与s中记录做匹配计算,然后再读第二块,因此读r的数据块不是连续读,所以每个块都需要seek),关系r的每一条记录需要与关系s中的每条记录做匹配计算,但是s只需seek一次(顺序读每一块,所以只需一次seek)
Block Nested-Loop Join
这个算法以
块
的方式而不是以记录的方式来处理。内层关系的每一块与外层关系的每一块成对处理,每一块中的每一个记录与另一个块中的每一个记录形成记录对,做条件匹配,满足条件的作为结果关系的记录
最坏情况:
传输块数
: b_r + b_r * b_s
Seek次数
: 2b_r
最好情况
传输块数
: b_r + b_s
Seek次数
:2
改进
:
读入外层关系的数据块时,可以按照内存大小M(设内存大小为M个块),一次读入外层关系的
M-2
个数据块,然后读内层关系的每一块与M-2个数据块的数据进行join条件的匹配计算。2表示留出来的内存空间给内层关系的数据块以及输出结果用。
b_r + \lceil b_r /(M-2)\rceil * b_s 传输 2\lceil b_r/(M-2)\rceil 次seek
如果join运算时,join的属性是内层关系的key,那么在外层关系与内层关系的记录进行匹配时,找到满足条件的第一个记录,算法就停止运行
对内层关系轮流做向前和向后的扫描,这种方法对磁盘块的读写请求进行排序,使得之前扫描的数据块留在内存中,采用LRU策略。从而减少数据传输和seek的代价(不太懂)
Indexed Nested-Loop Join
条件:join是等值连接或自然连接。内层循环的连接属性上有索引
最坏
情况:每次只能向内存读入外层关系的一个数据块
外层关系r的每一块都要读,因此
传输
br次,
seek
也是br次;对于r关系的每条记录,需要在s索引文件上进行查找,所以代价是 n_r* c ( n_r 是外层关系的记录数目, c 是使用join条件对内层关系s进行
单次查找的代价
(之前介绍的selection的计算代价)
join的
代价
: b_r * t_T + b_r * t_S + n_r * c
记录
数目较小的关系作为外层
关系,这样c的系数会小,
tT
和
tS
的系数都会小
Sort-Merge-Join
两个关系都按其连接属性排序
条件:等值自然连接
设 b_b 是为每个关系分配的缓冲块数,在join属性上具有相同值的记录是连续存放的,因此排好序的记录只需读一次,因此每一个数据块只需读一次。由于两个关系都只需读一遍,则
传输
的数据块数为 b_r + b_s ;
seek的次数
为 \lceil b_r /b_b \rceil + \lceil b_s /b_b \rceil
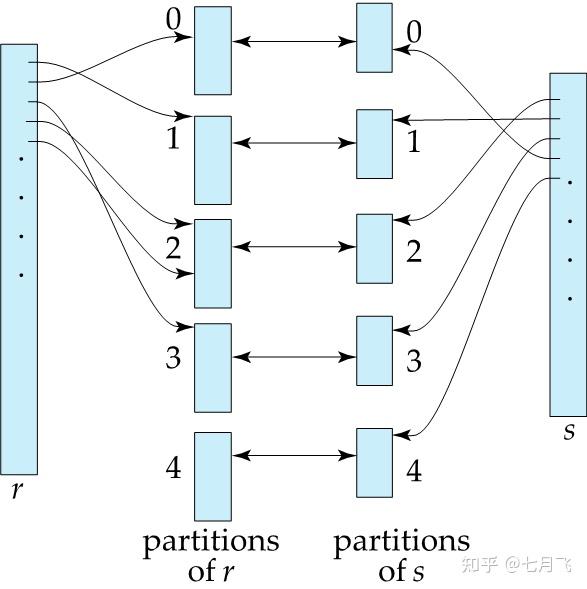
Hash Join
条件:等值自然连接
如果关系r的一个记录与关系s的一个记录满足join条件,它们在JoinAttrs(这是join的公共属性)就会有共同的值,经过hash函数的映射,给定i,他们必定在ri和si的划分中。这样进行join条件判断时,
不需要与其他划分中的记录进行比较
。s,r有n个partition
实现算法
:对于每一个i,依次完成以下步骤:
将si读入内存中,然后在JoinAttribute上建立内存中的hash索引。这个hash函数与生成划分的hash函数不一样
将ri的数据块依次读入到内存中,对于其中的每一个记录tr,应用内存中的hash索引找到si中的记录ti,然后输出拼接好的结果
其中s称作build输入,r称作探查probe输入
小关系
作为build更好
代价
:
传输
: 3(b_r + b_s) + 4 * n_h
seek
: 2(\lceil b_r / b_b \rceil + \lceil b_s / b_b \rceil)
递归传输: 2(b_r + b_s)\lceil log_{\lfloor M/b_b-1\rfloor}(b_s / M) \rceil +b_r + b_s
递归seek: 2(\lceil b_r / b_b \rceil + \lceil b_s / b_b \rceil) \lceil log_{\lfloor M/b_b-1\rfloor}(b_s / M) \rceil
上一篇:
数据库学习笔记(04): Relational Database Design
下一篇:
墨天轮2022年度数据库获奖名单
回复
举报
使用道具
分享
返回列表
发新帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
浏览过的版块
前端开发
快速回复
返回顶部
返回列表
 发表于 2023-3-25 20:14:31
|
显示全部楼层
发表于 2023-3-25 20:14:31
|
显示全部楼层