|
|
 发表于 2023-2-13 13:15:12
|
显示全部楼层
发表于 2023-2-13 13:15:12
|
显示全部楼层
导读:欢迎来到 StarRocks 源码解析系列文章,我们将为你全方位揭晓 StarRocks 背后的技术原理和实践细节,助你逐步上手这款明星开源数据库产品。本期 StarRocks 源码解析将介绍 Set 算子源码解析。
Set 算子又名集合算子,集合算子则用来实现 SQL 中的集合操作。本文将主要介绍 Union 算子、Intersect算子、Except 算子的工作原理,并进行源码分析。
在正式开始前,先简单了解下相关概念。
一、功能介绍
集合操作用于组合两个或更多 SELECT 语句的结果集 ResultSet,并要求每个 ResultSet 的列数和类型一致,StarRocks 中包含四种集合操作:
- UNION:取所有输入 ResultSet 的并集,会对输出 ResultSet 进行去重
- UNION ALL:同样取所有输入 ResultSet 的并集,但是不去重
- INTERSECT:取所有输入 ResultSet 的交集,会对输出 ResultSet 进行去重
- EXCEPT:取第一个输入 ResultSet 与其余 ResultSet 的差集,即输出 ResultSet 中的每一行只存在于第一个输入 ResultSet、不存在于其余 ResultSet 中,会对输出 ResultSet 进行去重
具体示例如下:
CREATE TABLE t1 (
`x` int(11) NULL,
`y` int(11) NULL
) ENGINE=OLAP
DUPLICATE KEY(`x`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`x`) BUCKETS 192
PROPERTIES ("replication_num" = "1");
INSERT INTO t1
VALUES (1, 1), (1, 2);
SELECT * FROM t1;
+------+------+
| x | y |
+------+------+
| 1 | 1 |
| 1 | 2 |
+------+------+
SELECT x, y, y FROM t1
UNION ALL
SELECT x, x+1, y FROM t1
UNION ALL
SELECT 10, 11, 12;
+------+------+------+
| x | y | y |
+------+------+------+
| 1 | 1 | 1 |
| 1 | 2 | 2 |
| 10 | 11 | 12 |
| 1 | 2 | 1 |
| 1 | 2 | 2 |
+------+------+------+
5 rows in set
SELECT x, y, y FROM t1 UNION SELECT x, x+1, y FROM t1;
+------+------+------+
| x | y | y |
+------+------+------+
| 1 | 1 | 1 |
| 1 | 2 | 2 |
| 1 | 2 | 1 |
+------+------+------+
3 rows in set
SELECT x, y, y FROM t1 INTERSECT select x, x+1, y FROM t1;
+------+------+------+
| x | y | y |
+------+------+------+
| 1 | 2 | 2 |
+------+------+------+
SELECT x, y, y FROM t1 EXCEPT select x, x+1, y FROM t1;
+------+------+------+
| x | y | y |
+------+------+------+
| 1 | 1 | 1 |
+------+------+------+二、术语约定
Chunk:按列存储的多行数据,一个 Chunk 最多包含 max_chunk_size 行数据,max_chunk_size 默认为 16384。算子之间传递和处理数据都在 Chunk 和 Column 维度进行。
三、Union 算子
3.1 UNION 转化为 UNION ALL
Union 相关算子只需实现 UNION ALL 操作,UNION 操作通过在 UNION ALL 算子基础上添加去重操作即可。即,UNION 等价于 UNION ALL + GROUP BY:
SELECT x, x, y FROM t1 UNION SELECT x, y+1, y FROM t1;
-- 等价于
SELECT c1, c2, c3 FROM (
SELECT x as c1, x as c2, y as c3 FROM t1 UNION ALL select x, y+1, y FROM t1
) tmp
GROUP BY c1, c2, c3;
3.2 总体流程
算子树中数据的流向如下图所示:
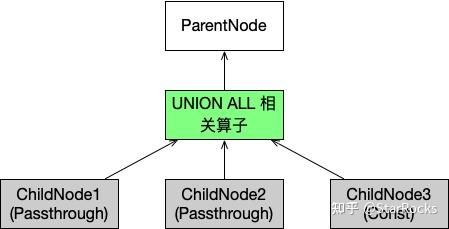
- 多个孩子算子节点,将 Chunk 发送给 UNION ALL 相关的算子;
- UNION ALL 相关的算子把输入 Chunk 经过必要的处理后,发送给父亲算子节点即可。
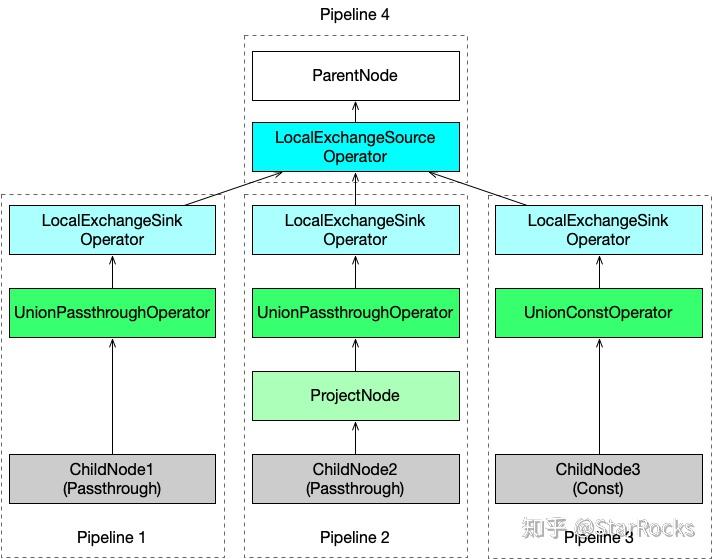
三种处理输入列的方式
UNION ALL 需要对输入每一列数据进行如下三种处理:
不需要任何处理,把输入的列直接作为输出列即可。对于这种情况,使用 UnionPassthroughOperator 进行处理。
输入的列需要进行表达式计算后再输出。对于这种情况,先将 ChildNode 的输出 Result Set 经过 ProjectNode 进行表达式计算后,同样使用 UnionPassthroughOperator 进行处理即可。即 ChildNode --(x) --> ProjectNode --(x+1)--> UnionPassthroughOperator-->(x+1)-->ParentNode。
没有输入的列,直接通过常量表达式计算得到输出的列。对于这种情况,使用 UnionConstOperator 进行处理。
多流合一
StarRocks 最新的 Pipeline 执行引擎,需要将算子树拆成没有分叉的多条 Pipeline。而多个 ChildNode 属于不同的 Pipeline,因此需要将多个包含 Union{Passthrough,Const}Operator 的 Pipeline 的输出数据输入给同一个 ParentNode 所在的 Pipeline。
这里使用 LocalExchange{Sink,Source}Operator 算子来进行处理。它的实现也比较简单,LocalExchange 作为中转站将每个 Chunk 以 Round Robin 的方式发送给 ParentNode 所在 Pipeline 的某个执行实例 Driver。
3.3 具体细节
UnionPassthroughOperator
UnionPassthroughOperator 的一个输入列可能对应了多个输出列。
形如 SELECT x, x, y FROM t1 UNION ALL ... 的 SQL,在输出 ResultSet 中会存在完全相同的两列。为了减少网络数据的传输,ChildNode 只会输出不同的列,即 ChildNode --(x,y) --> UNION ALL --(x,x,y)-->ParentNode。
由于每一个 ChildNode 输入 Chunk 的列顺序以及 UnionPassthrough 输出 Chunk 的列顺序可能不同,因此,使用一个 dst2src_slot_map,存储每一个输出列到输入列的映射关系。
- 如果一个输入列只对应一个输出列,直接将这一列输出即可
- 否则,需要将输入列复制为多列,再进行输出
UnionConstOperator
使用一个二维数组 _const_expr_lists,_const_expr_lists[j] 表示第 i 行、第j 列数据使用的常量表达式。
每次 UnionConstOperator 吐出一个 Chunk 时,会一次计算最多 max_chunk_size 行常量表达式,组装为一个 Chunk。避免每行常量表达式都产生一个小 Chunk。
四、Intersect 算子
4.1 总体流程
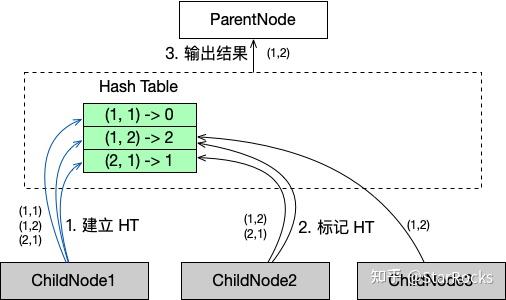
Intersect 算子主要使用 Hash Table 来实现。对于 N 个 ChildNode 做 Intersect 操作,将它们按照从左到右依次编号为 0, 1, ... , N-1。
使用第 0 个 ChildNode 的输出数据建立 Hash Table, Key 为所有列拼接起来,Value 为被其余 ChildNode 命中次数 hit_times。
对于其余第 i 个 ChildNode 的输出数据的每一行,在 Hash Table 中找到对应 Item,如果 hit_times==i-1,则将 hit_times+1;否则说明这个 key 没有被之前某个 ChildNode 命中。
遍历 Hash Table,将 hit_times==N-1 的 Key 组装为 Chunk,输出。
具体示例如下图:
4.2 详细流程
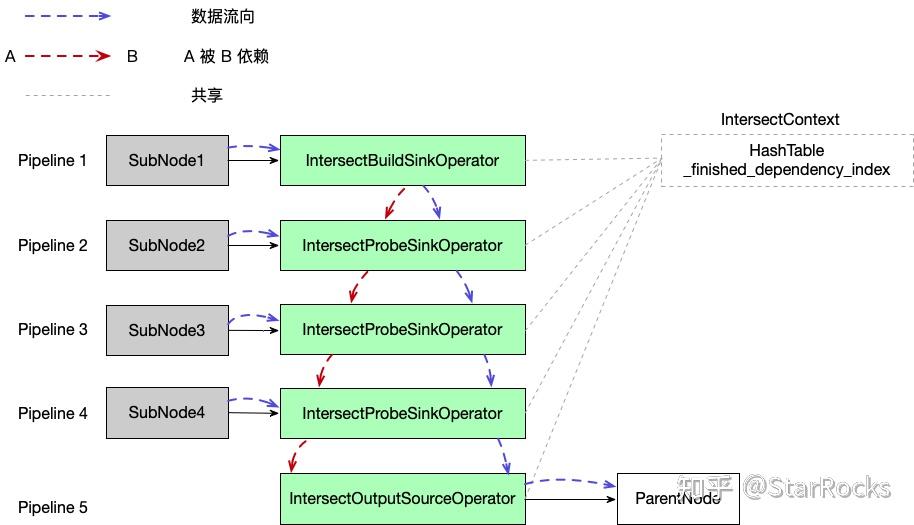
Intersect 相关的算子有三个:
- IntersectBuildSinkOperator 负责建立 Hash Table;
- IntersectProbeSinkOperator 负责标记 Hash Table 的 hit_times;
- IntersectOutputSourceOperator 负责遍历 HT,输出 hit_times==N-1 的 Key。
N 个 ChildNode 所在 Pipeline 需要串行执行,即
- IntersectBuildSinkOperator 先建立 HT;
- IntersectBuildSinkOperator 不再有输入数据后,IntersectProbeSinkOperator1 开始标记 HT;
- IntersectProbeSinkOperator{i-1} 不再有输入数据后,IntersectProbeSinkOperator{i} 开始标记 HT;
- 最后一个 IntersectProbeSinkOperator 不再有输入数据后,IntersectOutputSourceOperator 开始遍历 HT,输出 Chunk。
具体流程如下图:
4.3 具体细节
共享上下文信息
所有 Intersect{BuildSink, ProbeSink, OutputSource}Operator 共享同一个上下文对象,其主要包含 HashTable 以及一些辅助变量。
原子变量控制串行执行与可见性
使用一个原子变量 std::atomic<int32_t> _finished_dependency_index,控制串行执行。
- 第 i 个 IntersectProbeSinkOperator 需要等待 _finished_dependency_index==i-1 后,才能开始执行。即等待前一个 Intersect{BuildSink, ProbeSink}Operator 算子结束后开始执行
- 对于 N 个 ChildNode 进行 Intersect 操作,$$$$i\in[0, N-2]$$$$
- _finished_dependency_index 初始值为 -1,每次完成一个 Intersect{BuildSink, ProbeSink}Operator 加一
通过这种方式,只要第 i 个 IntersectProbeSinkOperator 发现_finished_dependency_index==i-1,那么它所依赖的 Intersect{BuildSink, ProbeSink}Operator 的写入操作对都它可见。
Buffer 存储 serialized Key
需要将每一列拼接为 Key,表现形式为一个 byte 数组。使用一个 Buffer 数组避免频繁分配释放内存。
- 其大小为 max_chunk_size * max_row_size,其中 max_row_size 为当前出现过的行的最大 bytes
- 每次拿到一个 Chunk,计算当前 Buffer 是否足够容纳所有 Key。如果不能则计算新的 max_row_size,重新分配一个新的 Buffer
Hash Table
Hash Table 使用 Prallel Hashmap,大多数场景下能够获得优于 std::unordered_map 的性能。
五、Except 算子
Except 算子与 Intersect 算子的实现逻辑几乎完全相同,包括:
- 拆分为三个算子:Except{BuildSink, ProbeSink, OutputSource}Operator;
- ExceptBuildSinkOperator、多个 ExcepProbeSinkOperator、ExceptOutputSource 之间串行执行。使用原子变量 _finished_dependency_index 串行执行与可见性。
不同之处只有一点:
- ExceptProbeSinkOperator 在标记 HT 时,将找到的 Item.hit 设为 true 即可。
六、总结
集合算子对多个 SELECT 语句的结果集进行交并差集运算。 其中:
- UNION ALL 将输入列通过 Copy/Move 的方式直接输出;
- UNION 在 UNION ALL 基础上使用所有列进行聚合;
- EXCEPT 使用第一个孩子节点的输入行建 Parallel Hash Map,使用其余孩子节点的输入行标记 Paralle Hash Map,输出没有被标记过的行;
- INTERSECT 使用第一个孩子节点的输入行建 Parallel Hash Map,使用其余孩子节点的输入行标记 Paralle Hash Map,输出被所有孩子节点标记过的行。
本期 StarRocks 源码解析到这就结束了,好学的你肯定学会了一些新东西,又产生了一些新困惑,不妨留言评论或者加入我们的社区一起交流(StarRocks 小助手微信号)。下一篇 StarRocks 源码解析,我们将为你带来 Runtime Filter 源码解析。 |
|

