立即注册
登录
搜索
前端开发
后端开发
虚幻引擎
U3D引擎
体感研发
数据库
论坛
BBS
本版
帖子
用户
麒麟软控
»
论坛
›
麒麟软控
›
数据库
›
用于CAZyme研究领域的数据库——dbCAN-seq数据库更新 ...
返回列表
发新帖
用于CAZyme研究领域的数据库——dbCAN-seq数据库更新
一朵闲云
一朵闲云
当前离线
积分
13
4
主题
5
帖子
13
积分
新手上路
新手上路, 积分 13, 距离下一级还需 37 积分
新手上路, 积分 13, 距离下一级还需 37 积分
积分
13
发消息
发表于 2022-12-1 18:06:49
|
显示全部楼层
什么是CAZymes?
CAZymes
(碳水化合物活性EnZymes)是一种
酶
,主要以
糖苷键
为目标,降解、合成或修饰地球上的所有
碳水化合物
。CAZymes在植物和植物相关
微生物
中非常丰富。
例如,
人体肠道
是富含碳水化合物的环境,碳水化合物降解细菌的多样性非常高。肠道微生物组的CAZyme组合组成了数以万计的附加基因。
CAZymes对
人类健康
、
营养
、
肠道微生物组
、生物能源、植物疾病和全球碳循环的研究极为重要。
在过去的5年里,大量的
微生物组
测序,来自各种生态环境的
数十万
个宏基因组组装基因组 (MAGs) 现在可以在公共数据库中获得。
例如欧洲生物信息学研究所的MGnify数据库和 IMG/M联合基因组研究所数据库。目前,没有数据库从微生物组MAG中收集
CAZymes
和
CAZyme基因簇(CGC)
并在网络上提供它们。
✦CAZyme研究对人体健康非常重要
与此同时,CAZyme生物信息学领域继续发展。现在可以推断CAZymes和CGCs的碳水化合物底物,这对应用微生物组非常有兴趣。例如,基于微生物组的个性化营养旨在使用
个性化饮食
干预策略来调节人体
肠道微生物组
,以
改善人体健康
。
预测患者肠道微生物组可能对哪些益生元聚糖做出反应的能力将对营养师和营养学家提出个性化饮食建议非常有用。
✦最新更新了dbCAN-seq数据库
最近在内布拉斯加大学的团队在Nucleic Acids Research发表的题为:“dbCAN-seq update: CAZyme gene clusters and substrates in microbiomes”的文章,更新了
dbCAN-seq数据库
( https://bcb.unl.edu/dbCAN_seq)
包括以下新数据和特征:
(i)来自
四种生态
(人类肠道、人类口腔、牛瘤胃和海洋)环境的9421个MAG~498000个CAZyme和~169000个CAZyme基因簇(CGC);
(ii) 通过
两种新方法
(dbCAN-PUL 同源搜索和 eCAMI 亚家族多数表决)推断的41447(24.54%) 个CGC的聚糖底物(这两种方法就4183个CGC的底物分配达成一致);
(iii)
重新设计
的CGC页面,包括CGC基因组成的图形显示、查询 CGC 和 dbCAN-PUL 的主题PUL(多糖利用位点)的比对,以及支持预测底物的 eCAMI 亚家族表;
(iv) 一个统计页面,用于根据底物和分类门组织所有数据,以便于CGC访问;
(v) 批量下载页面
总之,这个更新的dbCAN-seq数据库突出显示了预测
来自微生物组
的CGC的
聚糖底物
。
文章简介
dbCAN-seq数据库于2018年发布,提供了5349株细菌分离株基因组的
CAZyme和CGC (CAZyme基因簇)
序列及注释数据。
CGC是研究人员定义的一个术语,用于描述微生物基因组中含有CAZyme的
基因簇
。
PUL指多糖利用位点,是一个更流行的术语,描述利用复杂碳水化合物底物的
基因簇
,例如XUL(木聚糖利用位点),ChiUL(几丁质利用位点)和XyGUL(木聚糖利用位点)。随着CAZyme在生物信息学领域的发展,dbCAN-seq也紧跟步伐,推出了新的版本。
在dbCAN-seq数据库的
更新
中,主要取得了两个重要的进展:
(i) dbCAN-seq现在提供了
四个生态环境
(人类肠道,人类口腔,牛瘤胃,海洋)的微生物组的全面的CAZyme和CGC目录。
(ii) dbCAN-seq使用了
两种新的方法
来预测微生物组CGCs的底物,并提供了
底物查阅
功能,允许搜索针对不同微生物组中预测的特定底物的
CGCs
。
更新内容
1
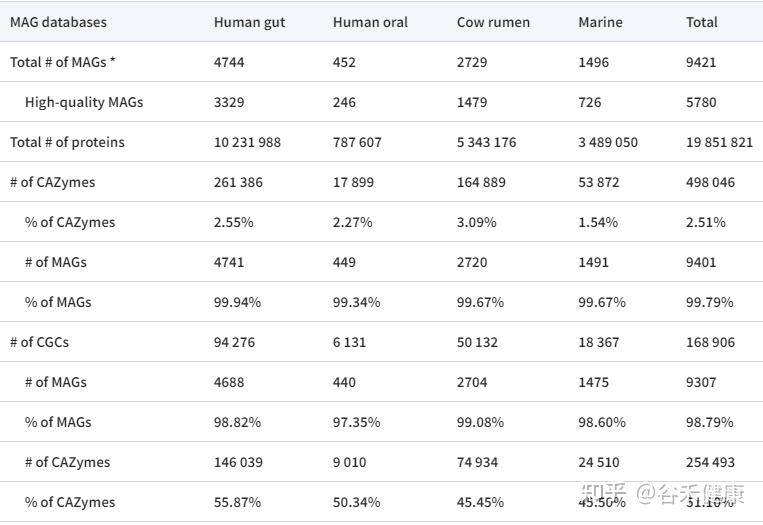
新增人类肠道、人类口腔、牛瘤胃和海洋微生物组的CAZyme及CGCs
对EBI MGnify数据库中的4个MAG数据集,选取其中质量最好的代表性基因组,如下表,一共9421个基因组,使用dbCAN2的run_dbcan程序进行注释,可见有近
50万个
蛋白质被注释为CAZymes。
人类肠道MAG中CGCs的CAZymes
比例最高
(55.87%),而牛瘤胃中CGCs的CAZymes
比例最低
(45.45%)。
2
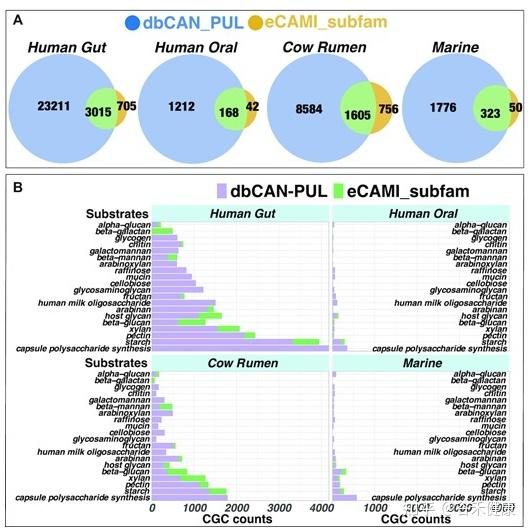
预测CGCs的碳水化合物底物
在预测出CGCs之后,研究人员开发了两种计算方法来推断它们的
糖基底物
,如下图。
第一种方法
使用BLAST比对CGCs的蛋白质序列(图A)与dbCAN-PUL的612个PULs的蛋白质序列(图B),选择BLAST总评分最高的最佳命中且至少有一个CAZyme与至少一个来自其它特征基因类别,如TC、TF等相匹配(例如图C),然后通过表S1,PUL→底物的映射文件,获知对应的底物;
第二种方法
使用eCAMI工具对CAZyme亚家族进行注释(图D),确定了CAZyme蛋白的eCAMI亚家族和EC数量后,根据eCAMI亚家族和EC编号建立的CAZyme亚家族→EC→底物的映射文件(表S2),使用简单的多数投票规则来推断CGC中的底物分配。
通过以上两种方法,目前dbCAN-seq数据库中新增的预测底物的CGC计数如下图:
图A为用dbCAN-PUL方法和eCAMI亚族方法注释CGCs的韦恩图。
图B各数据集中丰度top20的底物。
3
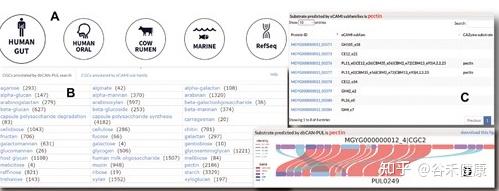
网页设计
dbCAN-seq的官网为:
https://bcb.unl.edu/dbCAN_seq
如下图,网站也新增了版块:
图A可选五个数据集。
图B可按目录浏览。
图C和D分别为支持通过eCAMI或dbCAN-PUL预测的底物查询对应的CGCs
dbCAN-seq数据库未来的发展
研究人员计划
每年更新
dbCAN-seq数据库,以包含
更多生态环境
的MAG数据集,例如来自小鼠、猪、山羊的肠道MAG,以及来自土壤和地球微生物组项目的MAG。
也会继续探索用于底物预测的方法,比如无监督机器学习方法,以预测自然界中
未知的底物
的新型CGCs。
相关阅读:
杭州谷禾信息技术有限公司创办于2012年,总部位于杭州,由几位浙江大学博士和教授创立,开发了大量高通量测序技术和生物信息分析方法,目前团队有多位生物信息和医学资深教授顾问,拥有优秀的研发团队和独立实验室,致力于利用高通量测序技术结合大数据和人工智能解决生物和医学问题。公司目前主要面向临床、健康和科研市场等,拥有多项自主研发的高通量测序和菌群检测专利,按照国际质量标准结合自动化处理样品和测试流程。领先推出基因检测和菌群检测相结合的健康检测服务,多年来服务于全国以及世界众多知名高校研究所、医院和上市公司。经过多年的积累,已完成超20万例临床肠道菌群样本检测,并构建了超过60万各类人群粪便样本数据库。公司为国家高新技术企业,杭州市“青蓝计划”企业,省级II级病原微生物实验室。
联系方式:400-161-1580
详情见官网:www.guhejk.com
上一篇:
开露营party用手电筒营造氛围?四色多彩照明,燃爆全场激情
下一篇:
数据库系统概论学习笔记(一)
回复
举报
使用道具
分享
返回列表
发新帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
快速回复
返回顶部
返回列表


 发表于 2022-12-1 18:06:49
发表于 2022-12-1 18:06:49