|
|
 发表于 2023-3-28 20:01:59
|
显示全部楼层
发表于 2023-3-28 20:01:59
|
显示全部楼层
本来想等到UE5正式版MotionMatching出来之后再写的,前几天发布的UE5.1版本的MotionMatching依然是实验版本,存在bug不少,不过看来核心思路与算法以及功能几乎不会变了,所以现在写也还好。对于MotionMatching的使用,主要分为两个部分,一是通过动捕获取动画资源,动捕数据需要遵循一些标准,并不是数据越多越好,二是通过已有动捕动画进行配置调参,而想要配置出出色的效果,就需要理解MotionMatching算法原理以及各个参数的意义,本文重点讨论后者内容,帮助大家快速理解UE5.1.1中MotionMatching的核心算法与参数的意义,以及如何调参达到想要的效果。 MotionMatching原理
关于MotionMatching原理已经有很多文章介绍过了,这里只说UE5中的MotionMatching原理:首先虚幻中的动画序列(Sequence)是由一个个的Pose组成的,每个Pose之间进行插值得到完整的动画,我们在使用动画状态机的时候是以Sequence为基础单位进行播放,这样就存在常见的滑步现象(实际输入和动画播放的动作不对应),以及动画衔接的问题,MotionMatching就是为了解决输入和动画不匹配的问题,表现,但是No Free Launch,它带来的一些问题就是:
这些都会在下面的参数配置中一一体现。
相比于Sequence,MotionMatching是以Pose为基础单位进行播放,如果使用动画状态机的话,比如在移动中会使用Walk或者Run相关的动画,那如何使用MotionMatching要怎么确定该使用哪个pose呢?这就引出了特征数据表的概念:虚幻引擎把每个需要使用的Sequence里的每一个采样Pose的特征数据提前记录下来,通过对比当前Pose以及动画库中每一个Pose的特征数据,通过一定运算选出最佳候选Pose,就是下一个需要使用的Pose了,说到这里就是关键了。
通过上面流程,说明MotionMatching是在“预测”接下来的动作,然后关于特征数据,我们可以大概猜测一下应该包含哪些信息,首先得有移动速度,不然没法确定是在走还是在跑,其次要有加速度,因为要确定动画的起步,停步,然后需要旋转,用于寻找旋转动画Pose,还有骨骼的Transform数据,防止动画的突变(用于解决当前脚的位置等)。
有了这些特征数据,接下来是做运算,如何利用这些数据计算出最佳的候选Pose,这里直接说UE5.1MotionMatching的算法:UE5将每个Pose的特征数据,包括上面提到的位置旋转等信息存在一个数组当中组成特征向量,然后将当前Pose的特征向量中的每一项数据与除去本身外所有Pose的特征向量中的每一项数据依此做减法,然后平方(防止出现负数),再计算每一项的和,就是切换到每一个Pose对应的Cost,取出Cost最小的Pose,就是下一个要播放的动作了。举一个简单例子:
现有两个候选Pose和一个当前的Pose,特征向量由速度和位置组成。
初始Pose0
| Pose | Velocity | Position | Cost | | Pose0 | (0,0,0) | (0,0,0) | | Pose1 | (1,0,0) | (1,1,0) | 3 | | Pose2 | (0,0,0) | (1,1,0) | 2(下一帧Pose) |
Cost(Pose1)=(Velocity1-Velocity0).x^{2}+(Velocity1-Velocity0).y^{2}+(Velocity1-Velocity0).z^{2}+(Position1-Position0).x^{2}+(Position1-Position0).y^{2}+(Position1-Position0).z^{2}
Cost(Pose2)= (Velocity2-Velocity0).x^{2}+(Velocity2-Velocity0).y^{2}+(Velocity2-Velocity0).z^{2}+(Position2-Position0).x^{2}+(Position2-Position0).y^{2}+(Position2-Position0).z^{2}
现在我们知道了核心算法,接下来开始为这个算法准备核心数据,首先是要有候选Pose的数据集,然后指定特征数据都有哪些就可以进行上述运算了,那么首先是Pose的数据集的设置。在准备数据之前,先开启MotionMatching的插件:
动画数据库
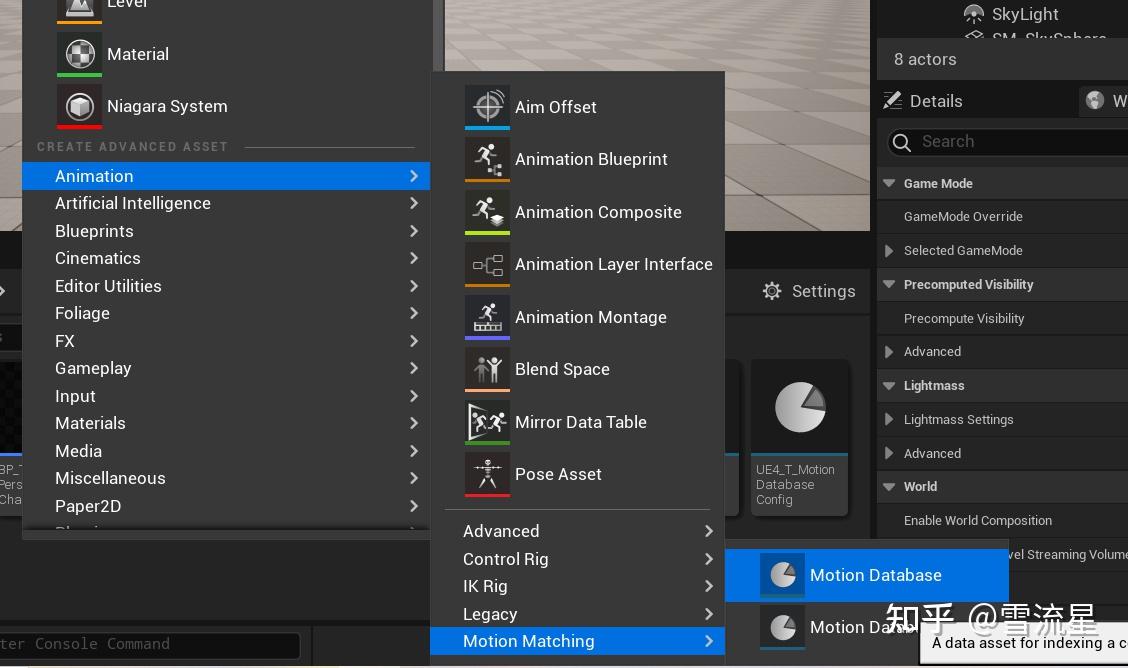
首先要创建动画数据库,用于将动画Sequence应用在MotionMatching上,所有候选Pose都来自于此,创建数据库的方式很简单,如下:
双击打开后会看到如下界面:
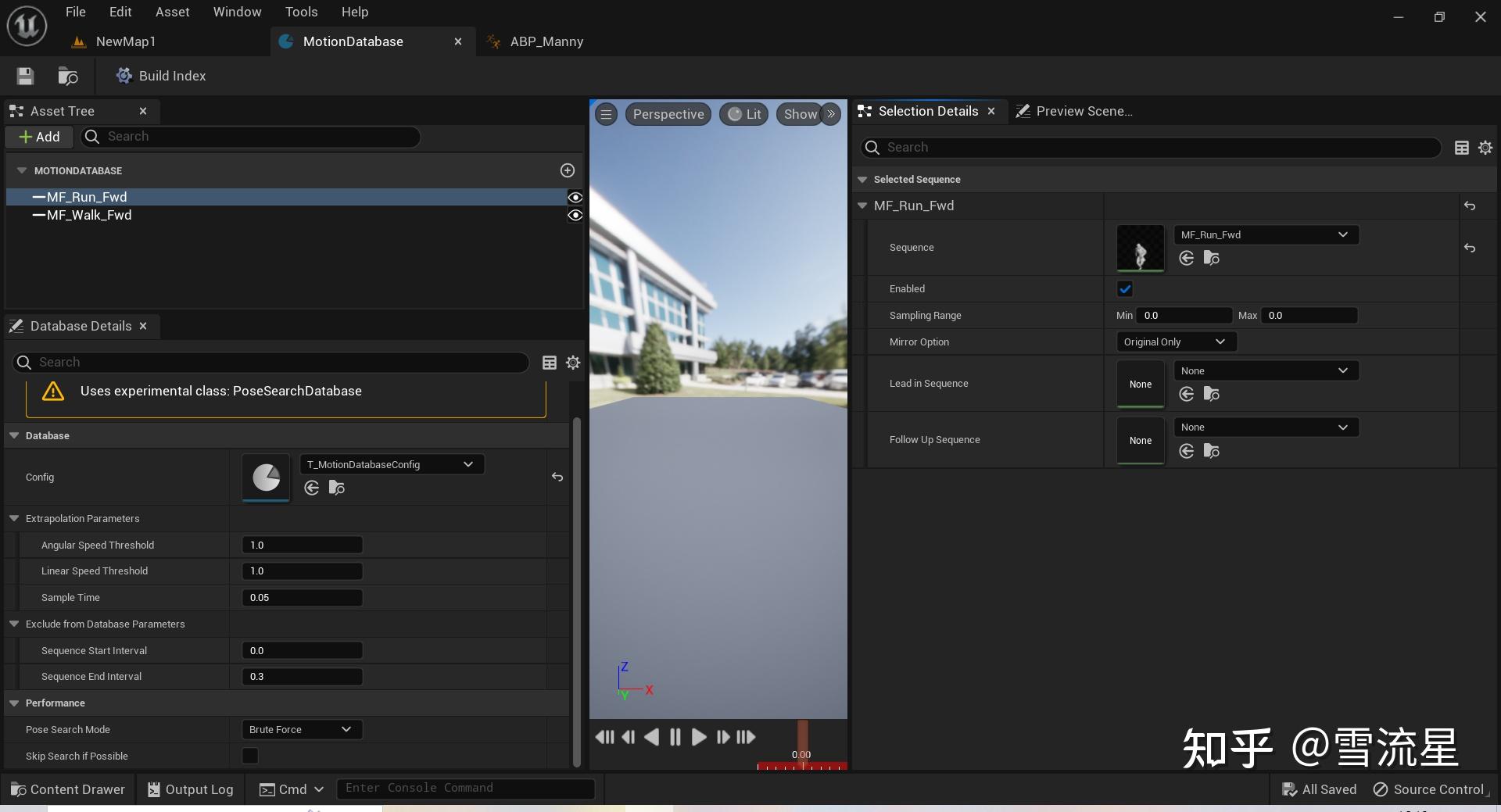
左侧窗口显示添加的动画序列集合,用于采样Pose,右侧可查看每个Sequence的详细信息:
Config:Pose特征向量配置表
ExcludeFromDatabaseParameters:
SequenceStartInterval=0.000000
SequenceEndInterval=0.300000
用于全局管理所有Sequence的起始和截止位置,每一个Sequence都会减去开始帧到SequenceStartInterval和SequenceEndInterval到结束帧的部分。
然后在属性面板有SampleRange参数,用于对单个Sequence进行裁剪,默认值为(Min=0.000000,Max=0.000000)不进行裁剪,这里的Min和Max是相对于Sequence原始数据长度的,取Sequence从Min到Max范围内的部分,其余部分裁掉,和ExcludeFromDatabaseParameters数据不一样。
执行的时候是先选择SampleRange范围内的参数,再利用全局的ExcludeFromDatabaseParameters进行剔除。
代码如下:
const UAnimSequence* Sequence = DbSequence.Sequence;
check(DbSequence.Sequence);
const float SequenceLength = DbSequence.Sequence->GetPlayLength();
const FFloatInterval EffectiveSamplingInterval = UE::PoseSearch::GetEffectiveSamplingRange(DbSequence.Sequence, DbSequence.SamplingRange);
FFloatRange EffectiveSamplingRange = FFloatRange::Inclusive(EffectiveSamplingInterval.Min, EffectiveSamplingInterval.Max);
if (!DbSequence.IsLooping())
{
const FFloatRange ExcludeFromDatabaseRange(ExcludeFromDatabaseParameters.SequenceStartInterval, SequenceLength - ExcludeFromDatabaseParameters.SequenceEndInterval);
EffectiveSamplingRange = FFloatRange::Intersection(EffectiveSamplingRange, ExcludeFromDatabaseRange);
}
这里只讲和采样截取相关的参数,这两个参数还有其他作用,到后面会讲到,其他的参数下面涉及到也会一一分析,方便理解。
通过裁剪之后,我们有了基础Pose数据,接下来要做的是指定特征向量数据,用于计算Cost。
特征数据配置表
创建特征数据配置的方式如下:
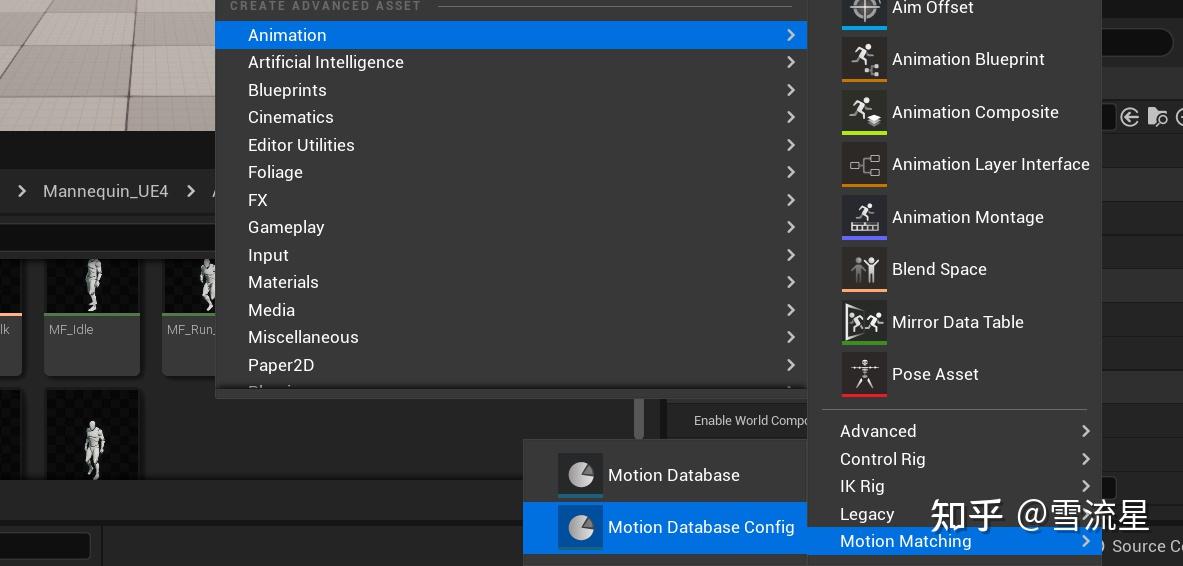
打开后参数如下:
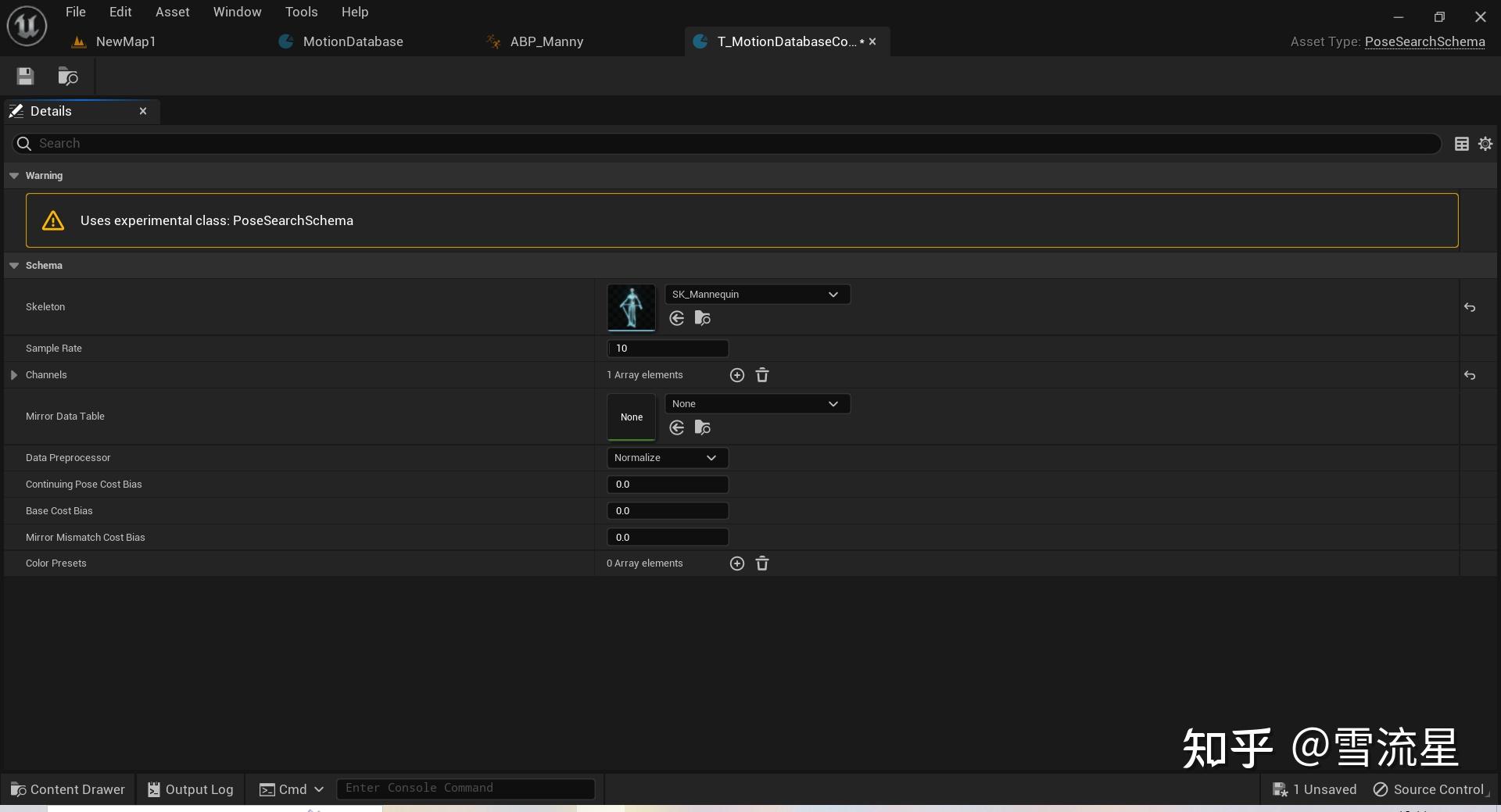
参数说明:
Skeleton:上面数据库动画对应的骨骼
Sample Rate:对每个动画数据库中的Sequence进行采样,如每秒10个Pose,Sample Rate越大,总共的Pose数越多,效率也就越低,当然Sequence数量和长度越大也是如此。
Channels:特征向量数组,根据上面的分析,这里一般需要指定输入移动的速度,位置,骨骼的位置等,这里配置比较灵活,没有固定选项,都是根据动画实际情况取选择那些特征数据,只不过一般情况下都需要那些核心数据。需要注意的是,这里填入的数据量越多,计算量也就越大,从算法原理上就可以表现出来。官方给的可选项非常多,供开发者根据项目情况选择,具体如下:
当点击添加数组元素时,看到这几个选项:
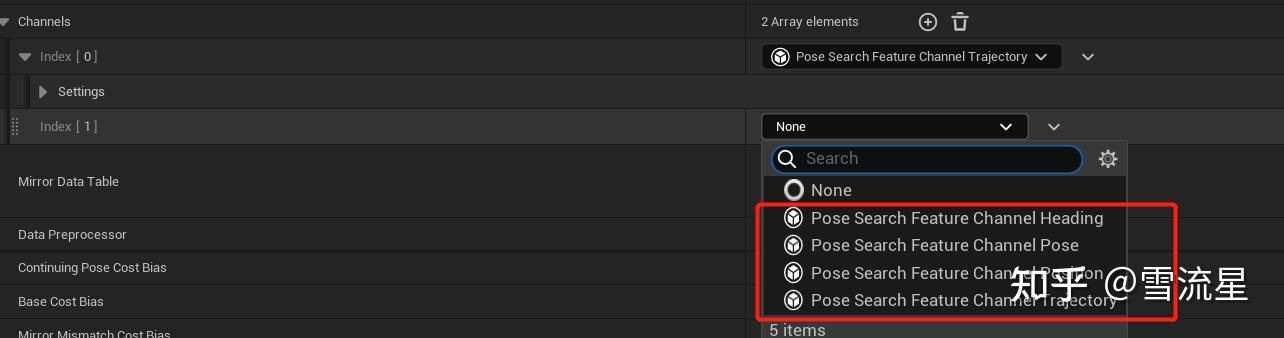
最重要的类型,用于指定当前移动的速度,位置等参数,参数有:
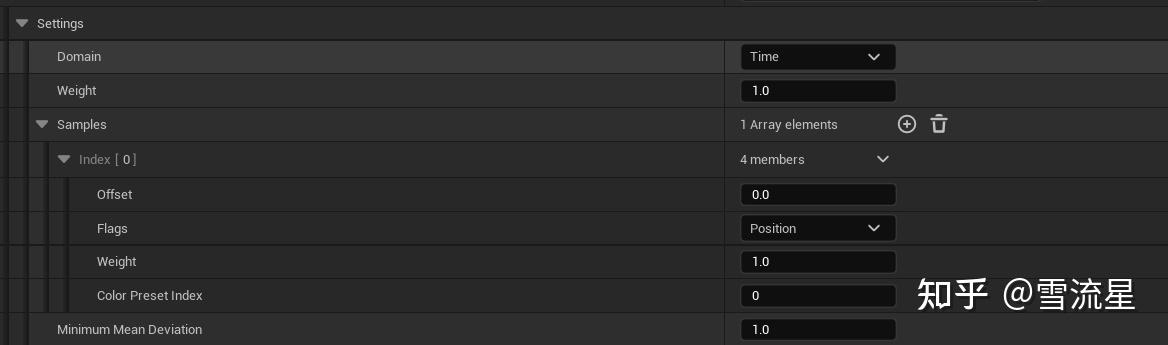
再强调一遍,特征向量数据是提取每一个Pose对应的数据,如Position,但只记录Pose本身的还不够,还需要记录这个Pose上下文相关的数据,这样候选Pose也更加精准,就是这个Pose附近的数据,也算作其Cost计算的一部分,所以就有了Domain的概念:
Domain:Time和Distance两种,Time是指以时间为偏移单位记录这个Pose周围的Pose数据下面的Offset就是相对于当前Pose时间点的偏移,那么,当前Pose的时间又是啥呢,他指的是这个意思:
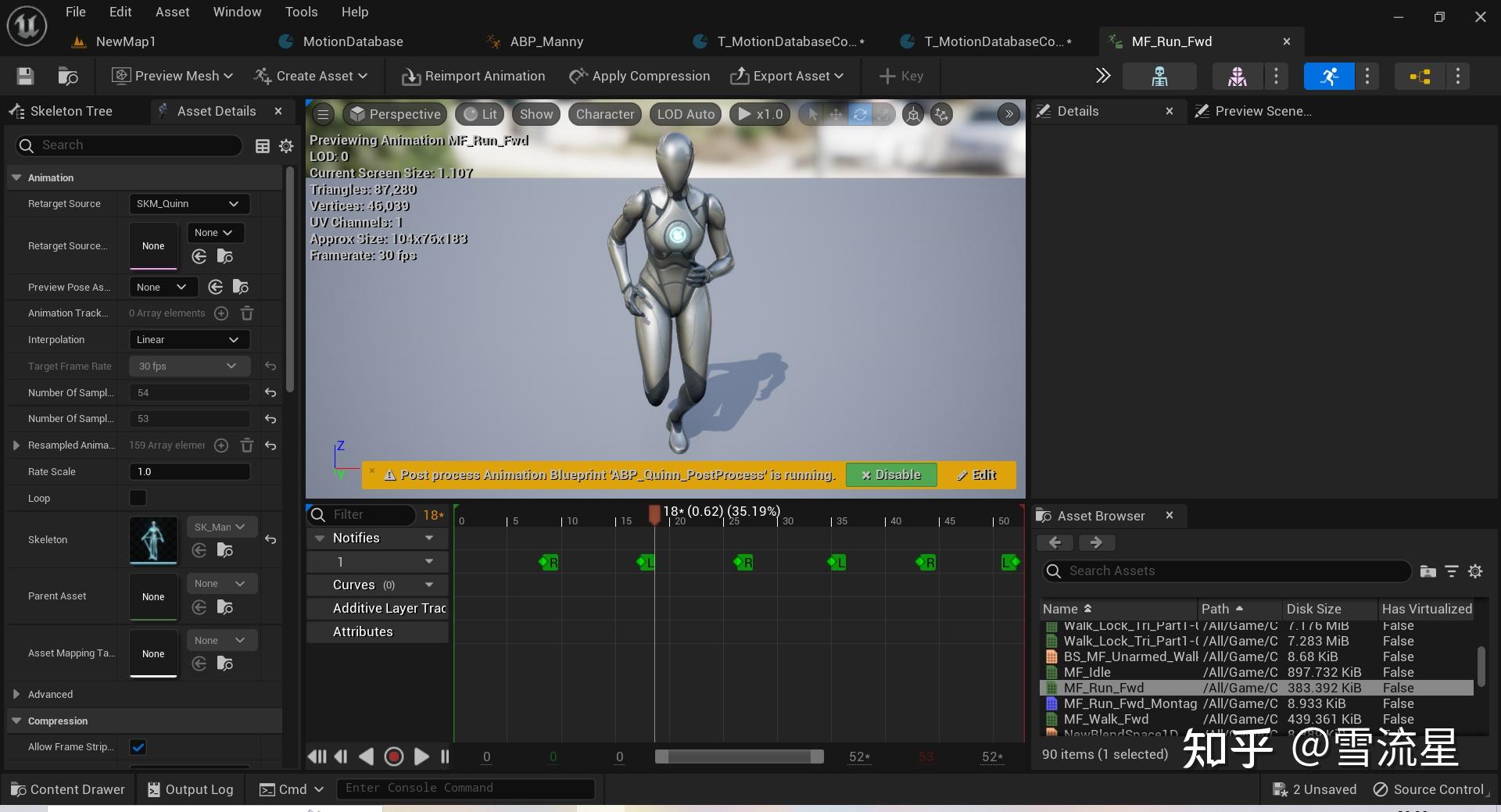
上图第18帧的时间是0.62秒,当然如果采样率是10的话,就不会采样到这一帧了,以第18帧为例,它的时间就是0.62秒,如果设置Offset为-0.1,就是指去记录0.51秒Pose的相关数据,如Position,当然记录哪些数据也是自定义的,对应的参数是Flags,具体有:
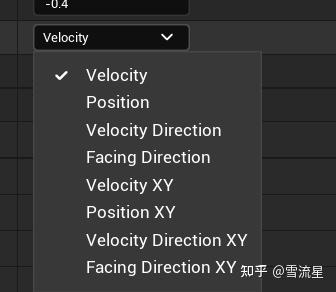
一般情况需要选的是1,2,3或者1,2,4项,3项和4项只是在不同坐标系下的值,选其中一个就好。
当Domain为Distance时,就是指以当前Pose为原点,选取相对于这个位置偏移Offset距离的Pose数据,所以比起Time很难把控对应Offset处的Pose到底是哪一个,一般选择Time的,但如果你非要使用Distance模式,也可以参考使用提取根运动位置信息的方式来确定Offset应该填多少,当然了前提是Sequence带有根运动数据。,不知道根运动的可以看我之前写的内容。
提取根运动的方式如下:使用Animation Modifier
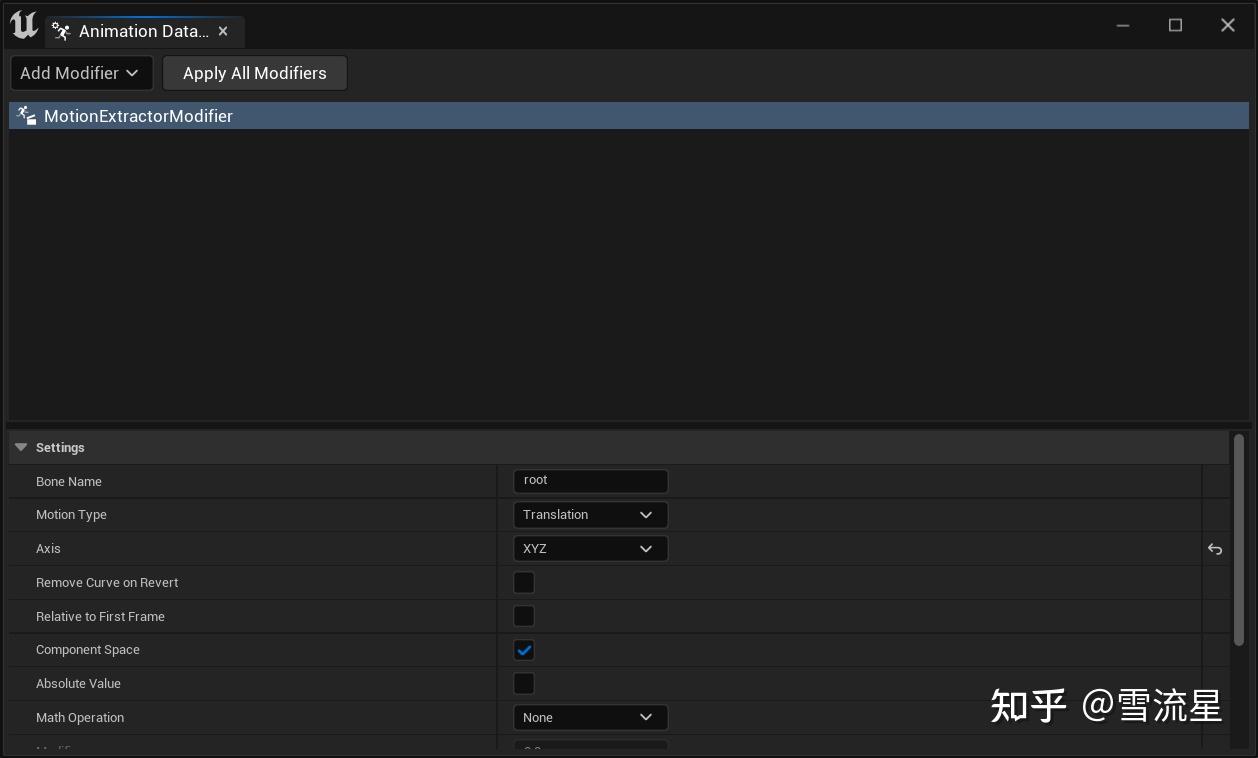

接下来思考的是:
- 2对于Sequence前几帧b和后几帧填写Offset很可能出现“越界”的情况,要如何处理
- Offset大概范围是多少,应该存在几组
根据曲线值填写Offset。关于Samples可以添加多个,每个设置不同的偏移,一般选择2-5组,范围是(-0.5,0.5),根据具体动作做一定范围内修改。那么说到这,聪明的读者可能就发现了,不对呀,如果我填Offset为-0.1,那对于Sequence 动画0.1秒内的Pose,采样-0.1秒不就出错了么,不存在对应的Pose;同理对于填Offset大于0的时候,比如0.5,那Sequence动画最后0.5秒的Pose采样的数据也是空的,这要怎么办呢,UE5的方式是根据动画进行预测,这就涉及到数据库中一些参数了,再看一下:
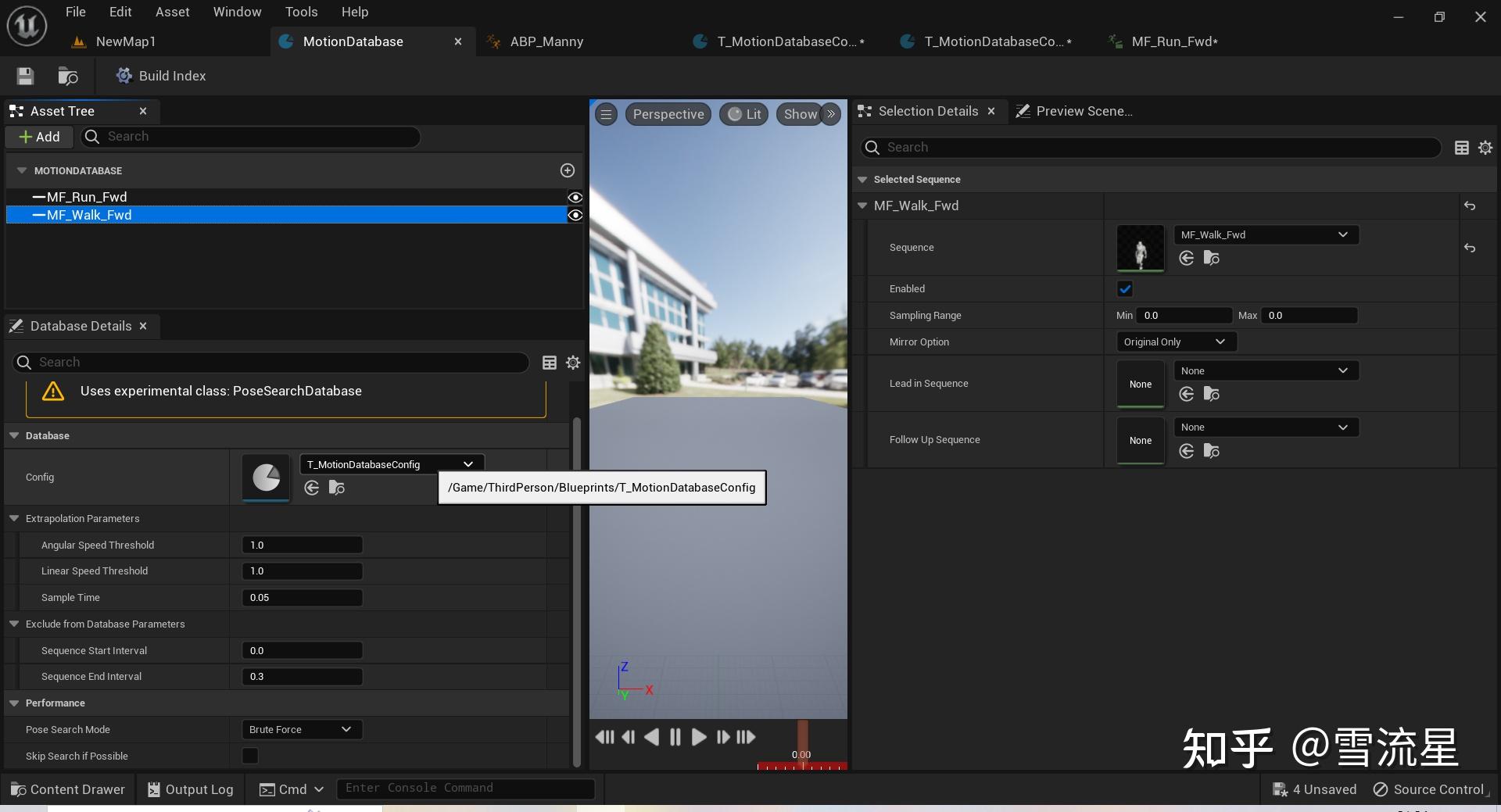
分情况讨论:
- 当Sequence为Loop的时候,这好办,0秒时采样-0.1秒的Pose,那就是采样Sequence EndPose的前0.1秒,因为是循环的嘛。
- 当Sequence不为Loop的时候,Lead in Sequence和Follow Up Sequence就会在这个时候被采样,作为当前Sequence的衔接头尾部分的Sequence
- 当Sequence不为Loop的时候,Lead in Sequence和Follow Up Sequence都为空时,会通过参数Extrapolation Parameters进行预测,预测位置,速度等信息,预测的方式就是使用Sample Time,在开始和结束的Sample Time时间内,去计算其速度等信息,并将其作为预测值付给对应的Offset位置处的特征数据。相当于计算在那段时间内的平均信息,当作预测数据。如果预测的角速度小于Angular Speed Threshold,线速度小于Linear Speed Threshold,就设为0,视为没有移动。
- 还有隐藏的一点,仔细观察我们会发现Sequence End Interval默认值是0.3,上面说过他的作用是裁掉所有动画结尾0.3秒内的Pose,为了不想在Search时选中一个Sequence快要结束的Pose,同时还有另一个大作用,就是使用裁掉的这部分当作特征数据,这样就不需要进行预测了,只对第三种情况会有好很多,毕竟预测的数据不准确,而对于前两种状况则无需考虑。从默认值是0.3也可以看出,官方希望我们Offset最大设置为0.3秒内,不过Time的Offset最大值最好设置为CharacterMovementComponent中角色从最大速度到0的加速时长。
最后是参数Weight:这一项所占的权重,很好理解,外面的Weight控制全局,里面的是只控制本身块局部权重,这个值一般保持默认就好,需要调整的话,下面会告诉细调参数的方法。
Color Preset Index:选项忽略就好,更改调试颜色的,没啥用。
上面记录的数据是关于根运动的移动,旋转,速度有关,那么接下来就需要记录骨骼的位置了,最关键的是脚的位置,以便区分左右脚。
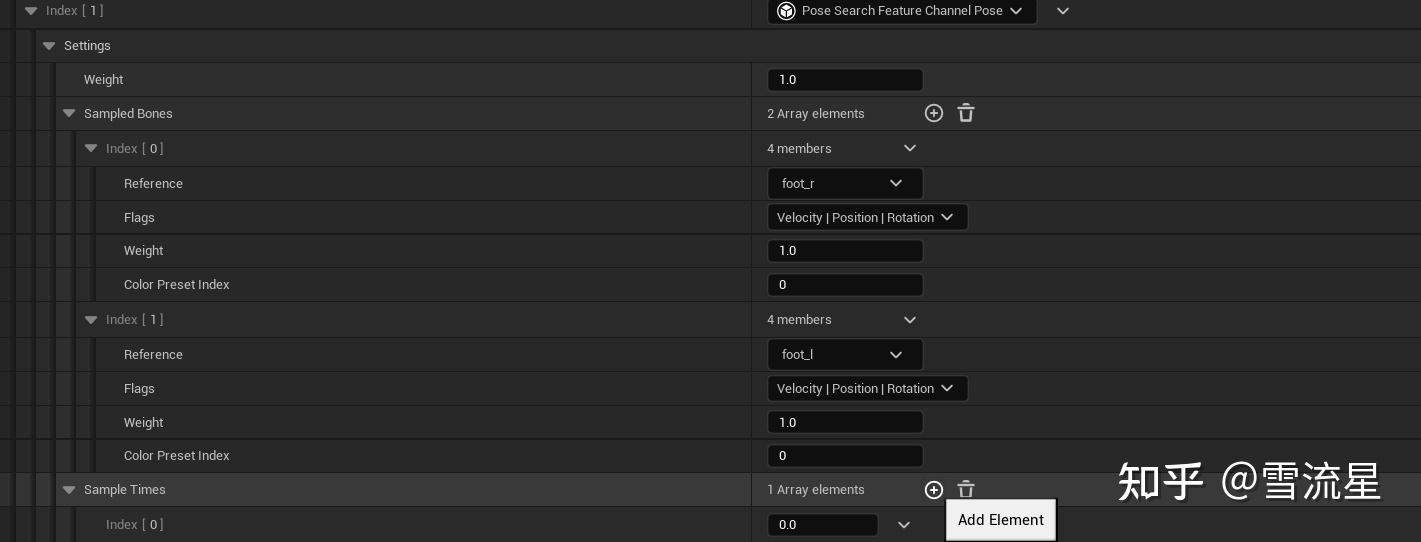
上面是记录了左右脚速度,位置,旋转的数据,本质上记录了左右脚骨骼的相关数据,数据相对于根骨骼。
大部分参数很好理解,很直观和上面说的差不多,需要注意的是SampleTimes,他是一个数组,你可以在里面填写采样偏移值,采样其他时间的数据,加上这个偏移时间进行采样,默认保持为0,就是采样Pose当前时间的数据。
关于Flag:

前三个很好理解,就是Pose骨骼的速度位置和旋转,第四个参数Phase(相位)有些不好理解,也不太好解释,Phase是读取Pose骨骼相对于Root的位置后,将动画序列中的最大值和最小值记录下来(做了平滑处理),中间过程用sin和cos进行模拟,下面是提取脚骨骼位置的数据:
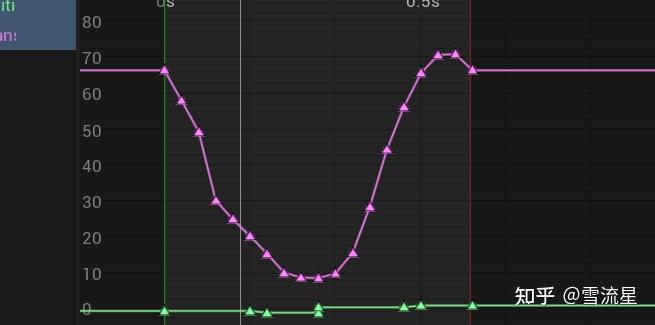
可以看到类似于Sin函数,下面是代码:
if (EnumHasAnyFlags(SampledBone.Flags, EPoseSearchBoneFlags::Phase))
{
CollectBonePositions(BonePositions, Indexer, SchemaBoneIdx[ChannelBoneIdx]);
// @todo: have different way of calculating signals, for example: height of the bone transform, acceleration, etc?
const int32 BoneSamplingCentralDifferencesOffset = FMath::Max(FMath::CeilToInt(BoneSamplingCentralDifferencesTime / FiniteDelta), 1);
CalculateSignal(BonePositions, Signal, BoneSamplingCentralDifferencesOffset);
const int32 SmoothingWindowOffset = FMath::Max(FMath::CeilToInt(SmoothingWindowTime / FiniteDelta), 1);
SmoothSignal(Signal, SmoothedSignal, SmoothingWindowOffset);
FindLocalMinMax(SmoothedSignal, LocalMinMax);
ValidateLocalMinMax(LocalMinMax);
ExtrapolateLocalMinMaxBoundaries(LocalMinMax, SmoothedSignal);
ValidateLocalMinMax(LocalMinMax);
CalculatePhasesFromLocalMinMax(LocalMinMax, OutPhases[ChannelBoneIdx], SmoothedSignal.Num());
}
static void CalculatePhasesFromLocalMinMax(const TArray<LocalMinMax>& MinMax, TArray<FVector2D>& Phases, int32 SignalSize)
{
Phases.Reset();
Phases.AddDefaulted(SignalSize);
float Certainty = 1.f;
float Phase = 0.f;
for (int32 i = 0; i < SignalSize; ++i)
{
CalculatePhaseAndCertainty(i, MinMax, SignalSize, Phase, Certainty);
FMath::SinCos(&Phases.X, &Phases.Y, Phase * TWO_PI);
Phases *= Certainty;
}
}
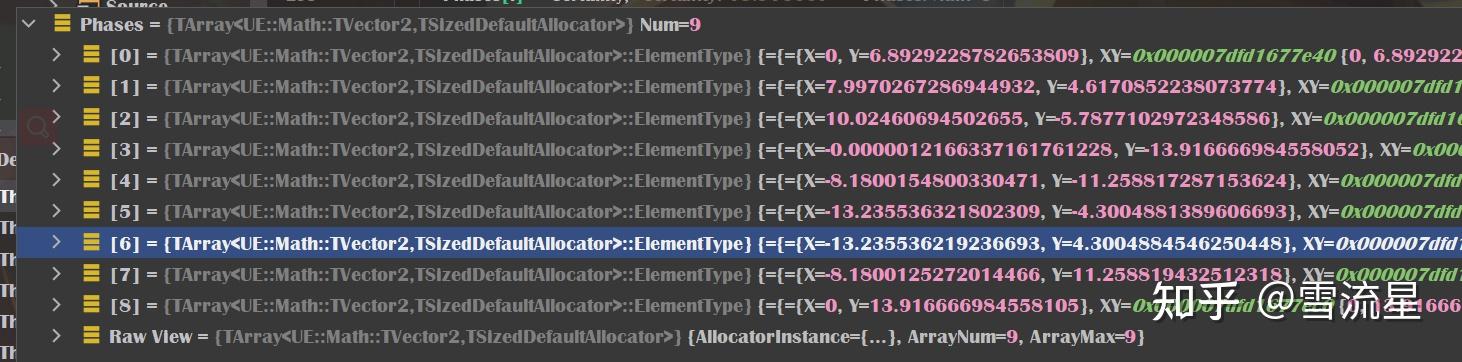
X记录的是Sin值乘Certainty,Y记录的是Cos值乘Certainty。可以看得出来数据在去掉系数后会模拟Sin和Cos曲线,运动曲线正是未了模拟脚的位置。这个特征向量是在Position基础上进行模拟的,所以如果已经将Position作为特征向量,那么我觉得这个没太大必要去使用。
本质和上面的Pose选项是一致的,只不过你可以选定某个轴,记录的是旋转数据
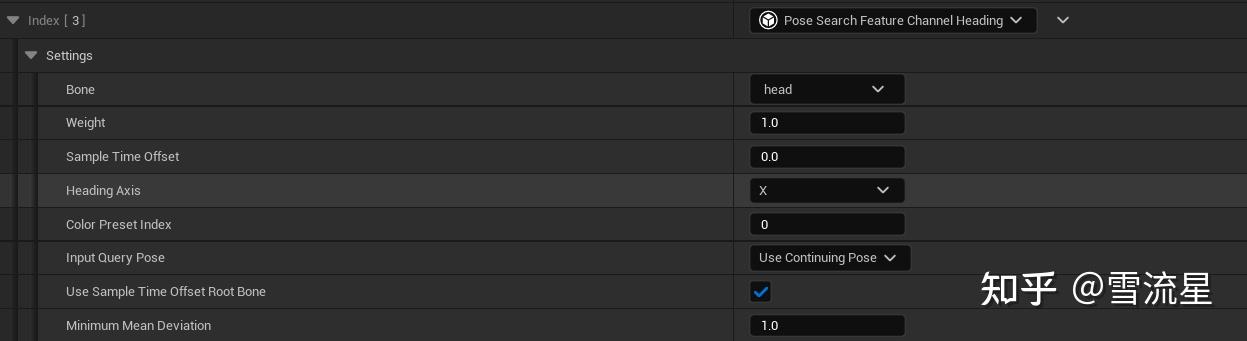
Input Query Pose用于选择使用预处理读取动画序列中的数据还是使用实际移动的History记录,Use Continuing Pose就是使用Sequence读取记录的数据,推荐这一种,比较省性能,而且充分利用数据,不需要History节点,Use Character Pose是实际移动用到的Pose数据,需要使用History节点进行保存。
HeadingAxis:
switch (HeadingAxis)
{
case EHeadingAxis::X:
return Rotation.GetAxisX();
case EHeadingAxis::Y:
return Rotation.GetAxisY();
case EHeadingAxis::Z:
return Rotation.GetAxisZ();
}
本质是读取骨骼Pose数据,和上面的Pose原理相同,不过只能读Position
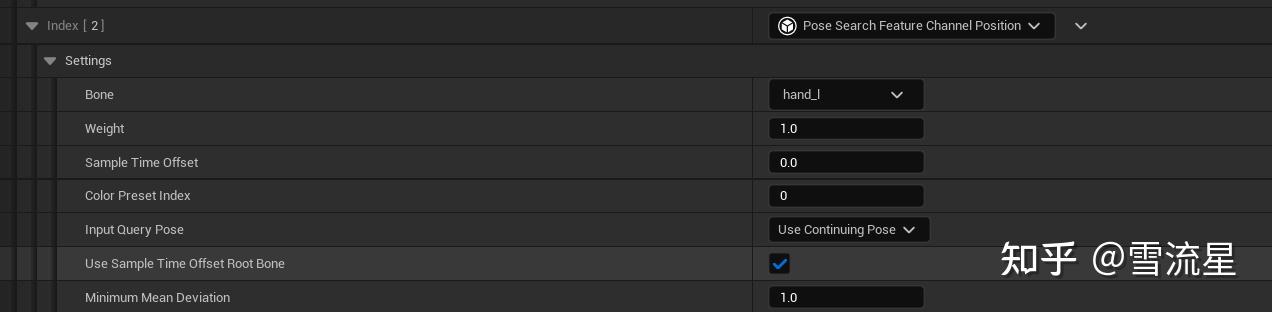
SampleTimeOffset就是在当前Pose时刻进行偏移SampleTimeOffset秒采样Position,其他的解释过了。
输入轨迹
上面提到过最重要的特征数据是Trajectory,Trajectory数据本质记录的是动画根运动数据,包括Root骨骼的Transform,Velocity等,那么他要和谁进行比较呢,自然是游戏中角色的实际移动信息,而角色的移动是Character Movement Component组件决定的,我们需要实时读取角色身上的相关数据与每个Pose的Trajectory数据进行对比计算,那么要如何读取实际移动的信息呢,而且因为Trajectory特征数据需要预测未来的移动状况(通过Domain),在记录角色实际移动的同时也要做到预测,虚幻提供了CharacterMovementTrajectory组件帮助完成此项任务,组件参数如下:
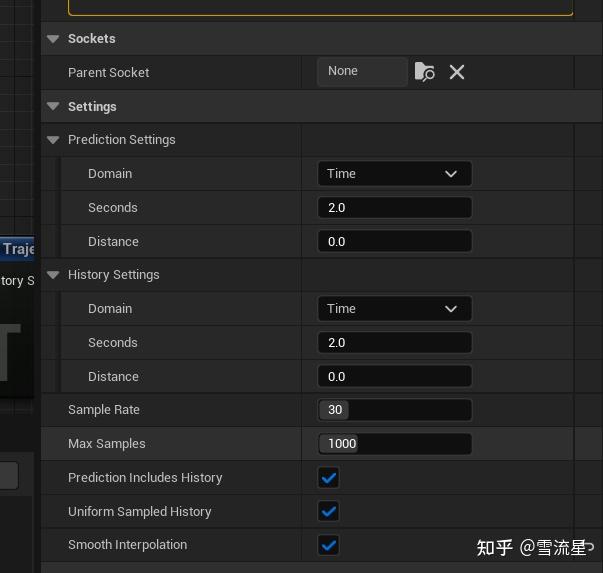
Prediction Settings和History Settings在说明了Trajectory特征向量数据后就比较好理解了,是根据Trajectory特征数据相对应的,如果Trajectory中使用了Time,这里也使用Time,然后填入预测和历史记录的总时长,如果填写2,就意味着会记录2秒内的相关数据,这里最好保持和Trajectory中的Offset最大值一致或稍微大一点,同时最好是根据加速度填写,当第n秒加速到最大速度,就可以填写成这个n,加速时长可以通过reminddebugger的Query Pose Vector确定,或者使用加速公式计算,不然预测太多也没意义,还浪费内存。然后是使用:
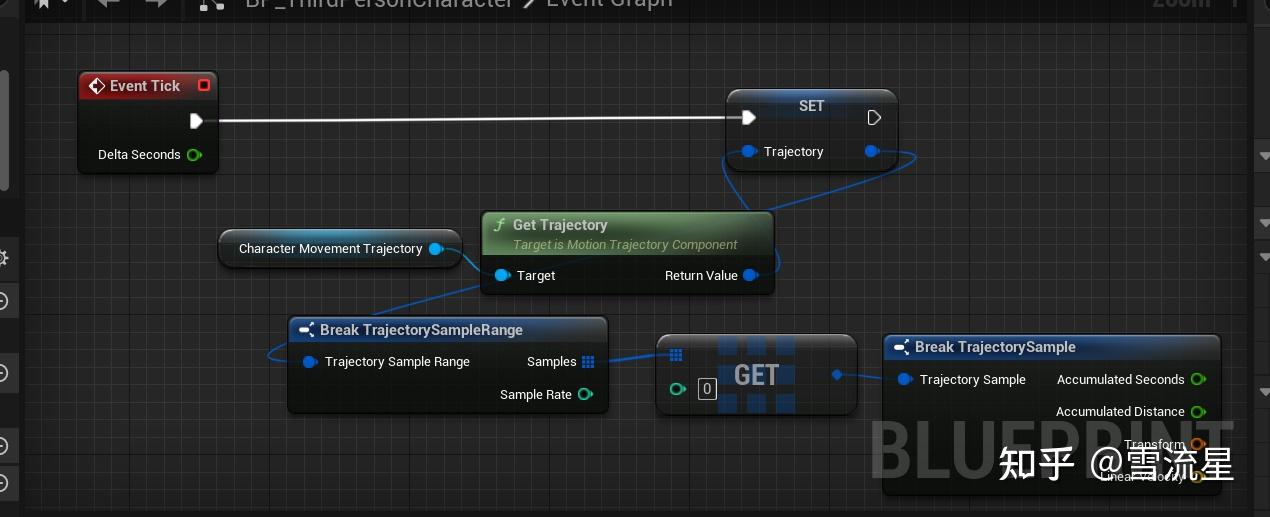
我们可以看到Trajectory保存了哪些数据。这个Trajectory变量需要给动画蓝图使用。
实际应用与调试
有了预测轨迹,动画数据库,特征向量配置,接下来就是实际应用MotionMatching了,使用很简单,在状态机里连下面的蓝图:
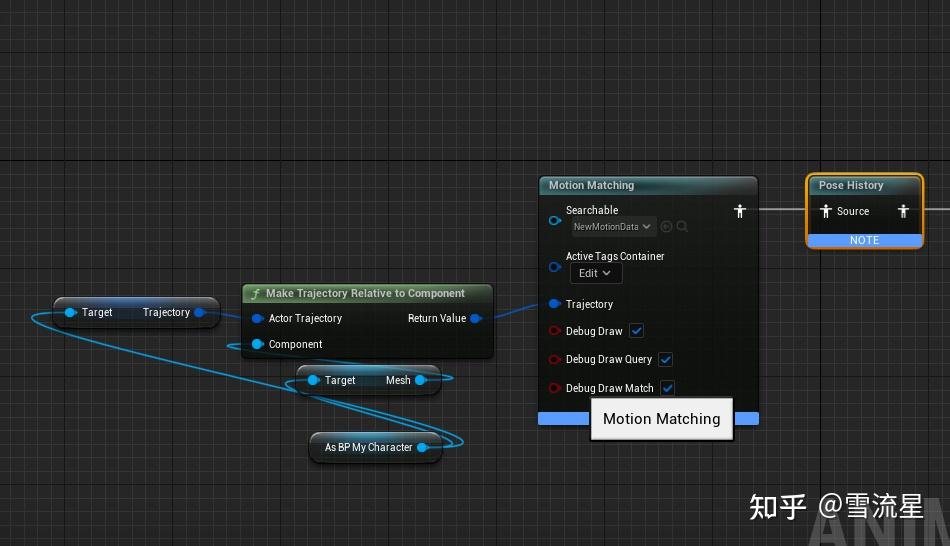
使用MotionMatching节点,传入的Trajectory就是CharacterMovementTrajectory的数据,不过需要注意的是Trajectory记录的是相对组件空间下的数据,要进行坐标变换,然后另一个节点是History,用于保存运行时之前采样的Pose,上面有说过,重点说一下MotionMatching节点的属性:
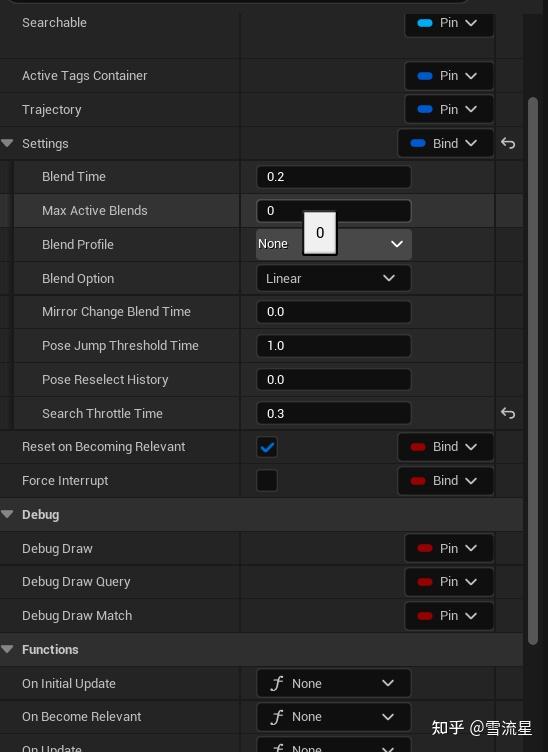
- Active Tags Container:目前版本还没有实际应用,忽略就好
- Search Throttle Time 最重要的参数,MotionMatching不会每一帧都去Search,因为性能会严重受影响,暴力算法每次都会遍历每一个数据库中的Pose,算法复杂度为O(n2),所以当距离上次Search超过Search Throttle Time时会进行Search,否则继续从当前选中的Sequence的Pose进行播放。如果播放到某个Sequence结束了也会进行强制Search。所以这个值越大越好,不过也并不意味着越小效果越高。
- Blend Time,Max Active Blends,Blend Profile,Blend Option,当进行Search后选择的Pose不是ContinuePose,就需要混合,这些参数用于Pose混合。
- Mirror Change Blend Time如果选中了镜像动画Pose,那么会使用这个值代替BlendTime进行混合,不过要大于0
- Pose Jump Threshold Time 在Search中找到的最佳Pose在时间上距离当前Pose没超过Pose Jump Threshold Time,就不进行跳转Pose,继续从当前Pose进行播放动画
- Pose Reselect History: 前Pose Reselect History秒被选中的会被忽略,不去选择。
要调整好Pose Jump Threshold Time和Pose Reselect History,会避免很多错误结果。
有了上述准备之后,就可以跑MotionMatching了。
不过接下来才是重点:调Pose权重参数
先理解特征数据几个参数选项:
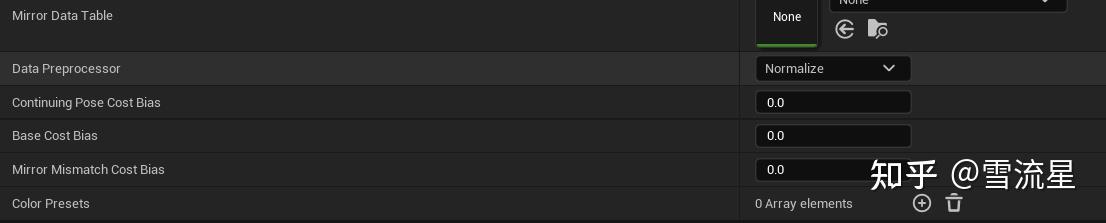
- Data Preprocessor 是否对特征数据进行Normalize,防止某项权重过大会忽略其他项,保证每一项权重均衡
- Continuing Pose Cost Bias,Continuing Pose是指,在Search时正在播放Sequence的Pose的下一个Pose,Continuing Pose Cost Bias调大就意味着希望Search的过程尽可能保证姿势的衔接,防止频繁跳转出现错误
- Base Cost Bias 会给每一个Pose的权重都加上这个值,感觉好像没用,实际上他的作用体现在使用Animal Notify State进行重写这个值的时候
- Mirror Mismatch Cost Bias 给所有镜像动画额外的叠加Cost,镜像动画后面会说
上面说的全是全局控制的方式,接下来说对某个动画单独修改Cost的方式:
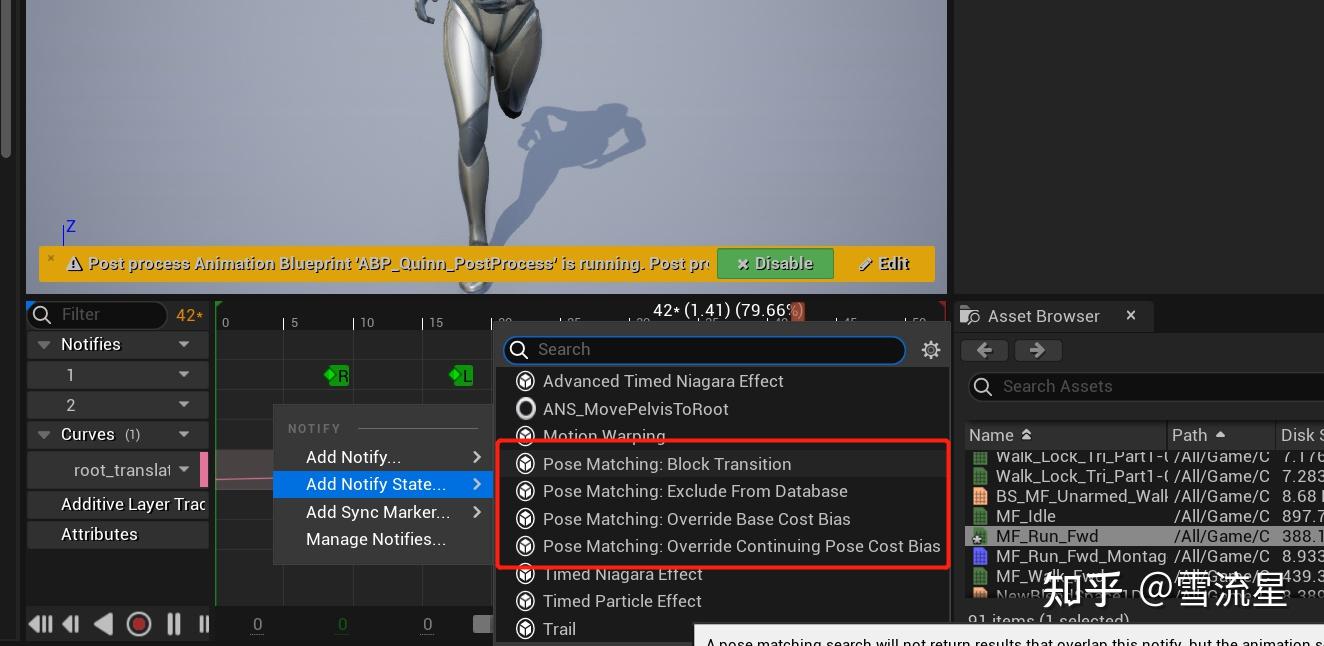
我们可以对单个动画做一些操作:
- Block Transition :防止Search的时候进行跳转,即标有Block Transition标记的Pose,会被忽略掉
- Exclude From Database:上面说过全局删减首尾部分或者单个动画修剪首尾部分,带有Exclude From Database的片段会直接从数据库中剔除掉,不希望被使用的Pose
- Override base cost bias:上面有控制全局的,这个是对全局的值进行覆盖,比如希望某个片段优先被使用或者少使用,需要用到这个
- Override Continuing Pose Cost bias:重写上面Continue Cost的值
现在,明白了那些参数的意义,但问题的关键是,我要给他们设置多少值呢?这就需要动画调试的超级利器Remind Debugger了。
开启方式如下:
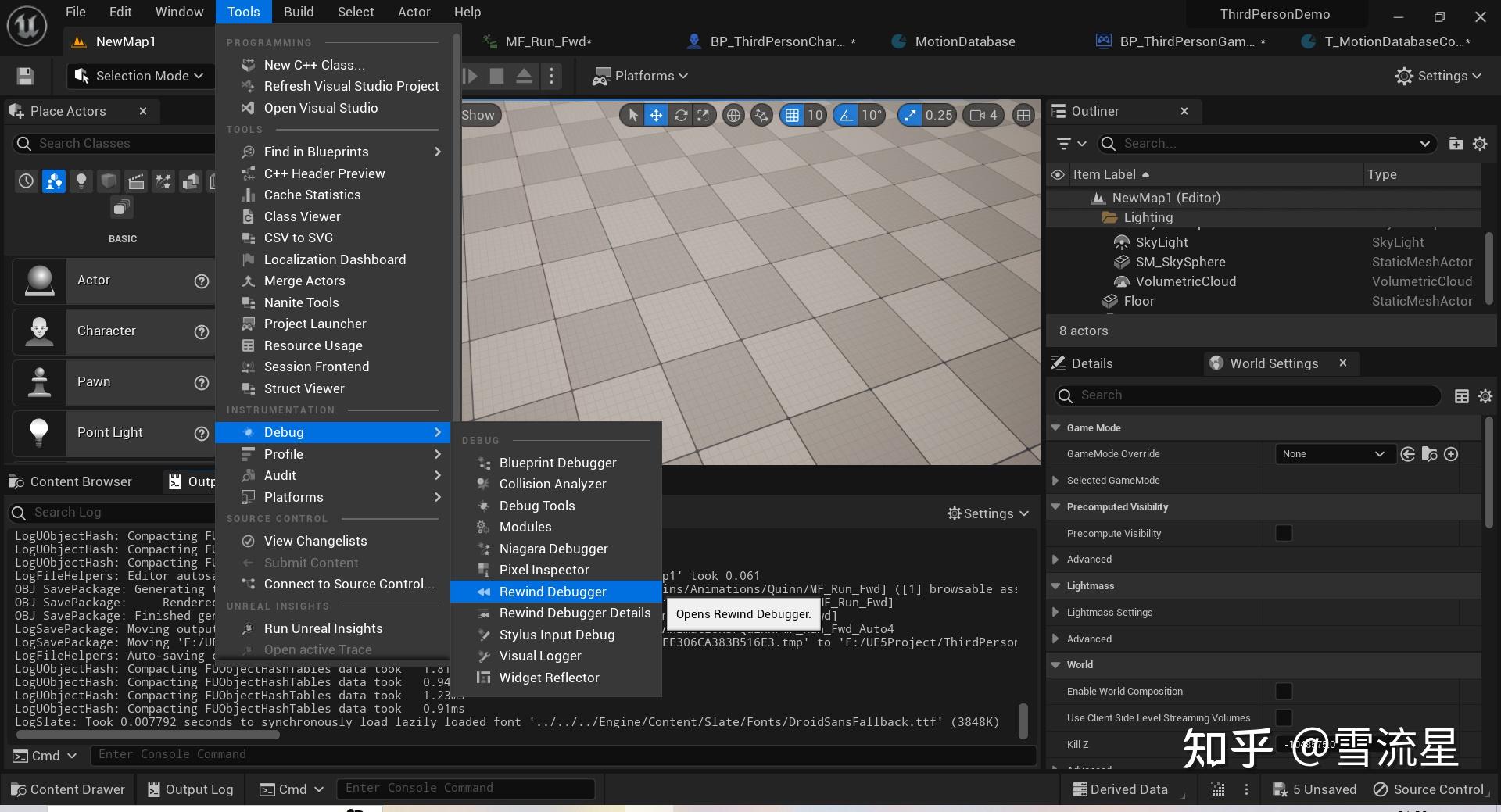
使用方式:运行后点击红色录制按钮,然后移动角色,左侧会显示记录的Actor列表,然后暂停游戏,停止录制,拖动滑动条查看录制过程数据。此工具不仅仅可以调试MotionMatching,还可以调试状态机和动画切换详细信息,只不过有了它,MotionMatching调参才真的容易很多。
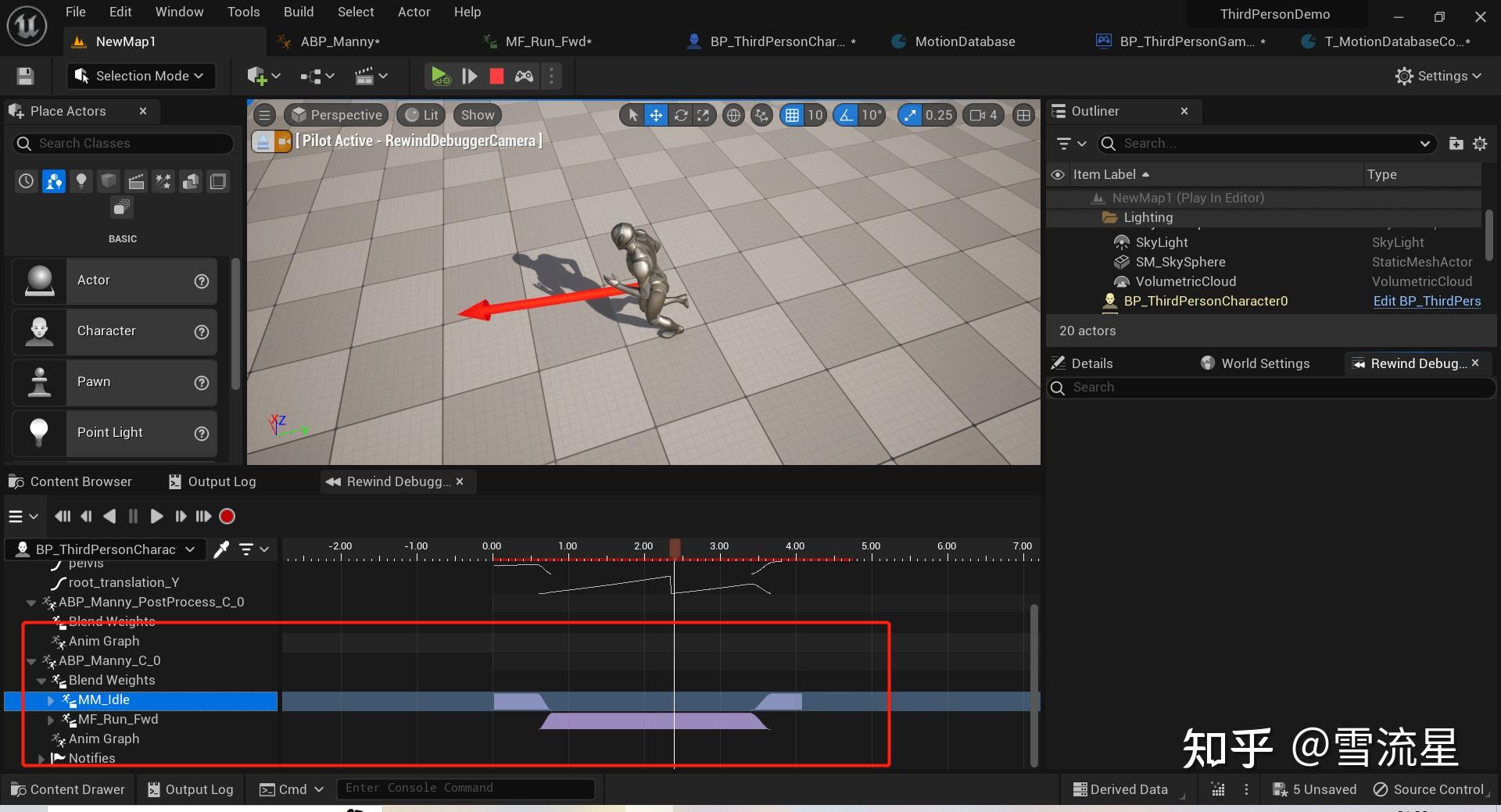
想要调试MotionMatching还不够,需要开启调试MotionMatching选项,命令是:
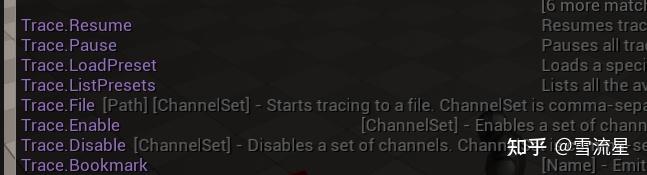

可以使用Trace.Stats查看是否有PoseSearch了,有了之后,RemindDebugger才能记录MotionMatching,可以看到PoseSearch轨道,我们在输入移动可以看到他具体使用了哪些Pose,什么时候执行了Search,以及PoseCost和叠加权重,在Remind Debugger Detail可以查看:
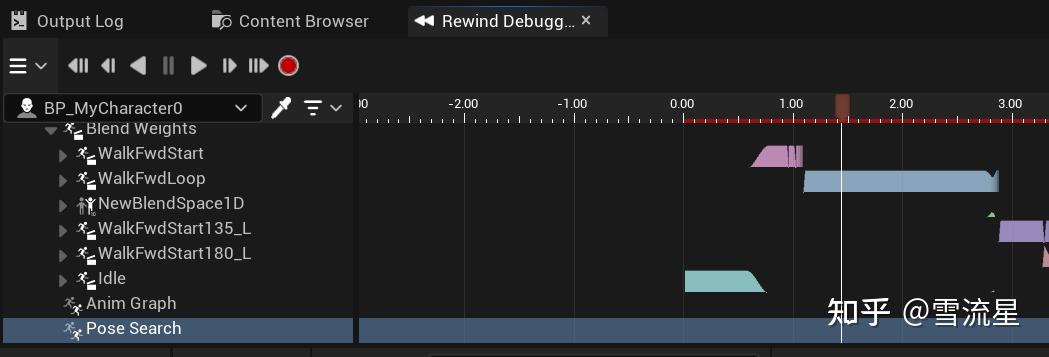
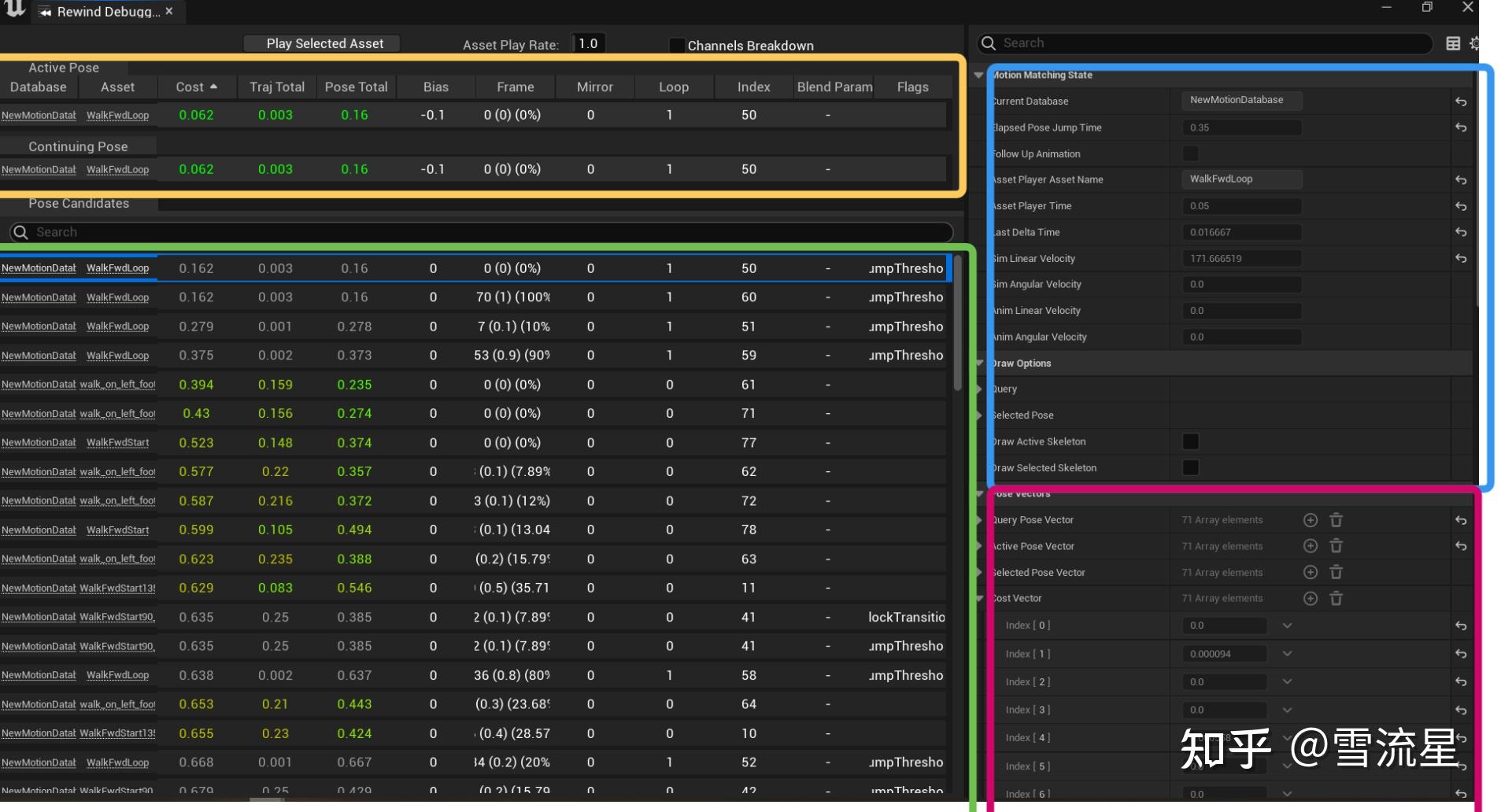
界面介绍:
黄色部分显示选中的Pose信息,最上面的Channel BreakDown可以展开每一项特征数据的Cost,ContinuingPose是衔接动画Pose的Cost,大部分情况我们都希望使用这一项,所以列在上面;Bias是我们手动设置的Cost叠加数据,可以全局更改,也可以分动画更改;
绿色部分是用堆维持的Cost排序,从优先级高到低,如果我们希望使用某一个Pose,但是他的Cost太小了,我们就可以在这个区域找一下它Cost的数据是哪一项造成的,粉色区域为详细数据,数组的大小取决于特征数据添了多少,就是,Position或Velocity就会占用三位,Rotation是6位,都会列在粉色区域的特征数据表内。
粉色区域:
Query Pose Vector:想要的目标数据,根据输入获取
Active Pose Vector:当前选中的Pose数据,包括位置旋转等,就是黄色区域的Pose
Selected Pose Vector:只有选择绿色区域中的一项后这个才会显示数据,显示选中的Pose详细数据
Cost Vector:选择绿色区域中的一项的Pose Cost数据
蓝色区域:
Elapsed Pose Jump Time:距离上一次Search的时间
其他的都是选中的Pose当前信息,很好理解
然后还有Debug模块:
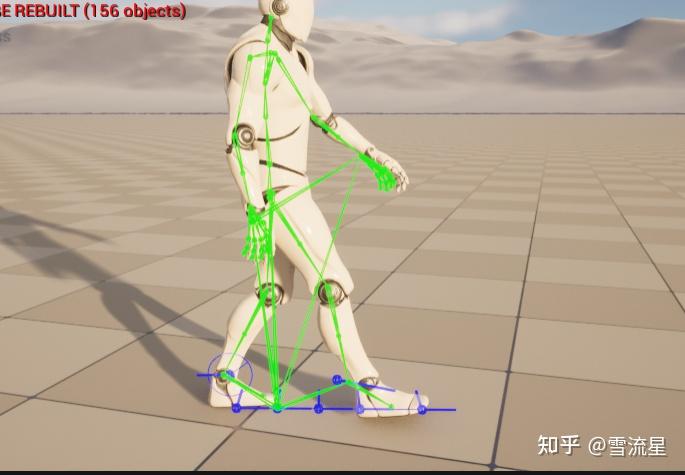
将特征数据可视化显示,更加直观。
有了这个工具,就可以快速调试出自己想要的效果了。这里总结了下推荐的几种设置:
1 转弯的时候尽量使用Block Transaction事件防止频繁跳转
2 处理基础移动轨迹数据外,增大对关键位置的权重,比如脚的位置和旋转,如果头部或者其他某根骨格的旋转或者运动也比较明显,最好也加进去,不仅仅是脚骨骼。
3 尽量给Continuing Pose额外Cost减成,优先使用,具体减多少对比remindDebugger进行适量修改
lead in sequence和follow up sequence能设置就设置,原理和作用说过了,包括loop动画
4 调试完成想要的效果记得去掉没用到的Pose和Sequence,也是使用remindDebugger查看哪些没用到
5 慎重修改Cost Bias,如果改,最好也在Sequence标注事件去改
性能优化
刚才说了暴力算法时间复杂度比较高,有一个Search Throttle Time参数可以减少Search次数,不过这不是关键,核心是要降低算法复杂度,官方提供了KDTree进行优化,配置在Database上(Database最后需要讲的参数):
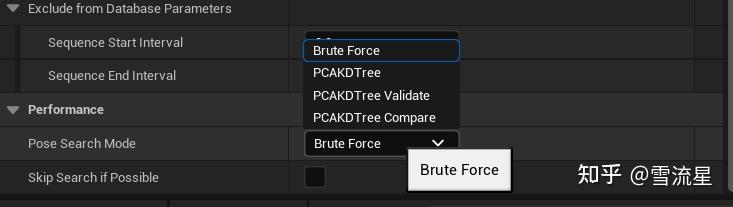
- Pose Search Mode:选择算法,两个,一个暴力算法,一个KDTree,下面两个本质还是KDTree,只不过多了调试和合法判定。KDTree底层调用的是nanoflann库,没细研究过,有兴趣的话可以自己看看。
- KDTree参数 Number Of Principal Components:切分维度,如果是2就是平面分割
- KDTree参数KDTree Max Leaf Size 最大叶子深度,用于终止分割条件限制
- KDTree参数KDTree Query Num Neighbors,选出的最重要参与查询的Pose数量,从这里面选出最佳Pose作为Search结果。
- Skip Search if Possible 这个参数会记录每次Search的最小值,如果没超过最小值就会跳过Search,个人感觉不是很合理的选项,所以不要勾选。
优化数据
除了优化算法外,我们应该还需要尽量减少pose数量和特征向量数量,通过调试之后,发现某个特征向量的值都是一样的,或者影响很小,就完全可以抛弃,对于Pose,通过RemindDebugger也可容易看到实际使用了那些Pose,那些不需要的就用ExcludeFromDatabase进行剔除,也会对性能带来提升
资源扩展应用
上面说过数据库中需要添加Sequence,除此之外还可以对Blend Space进行采样,下面详细介绍一下。
使用BlendSpace
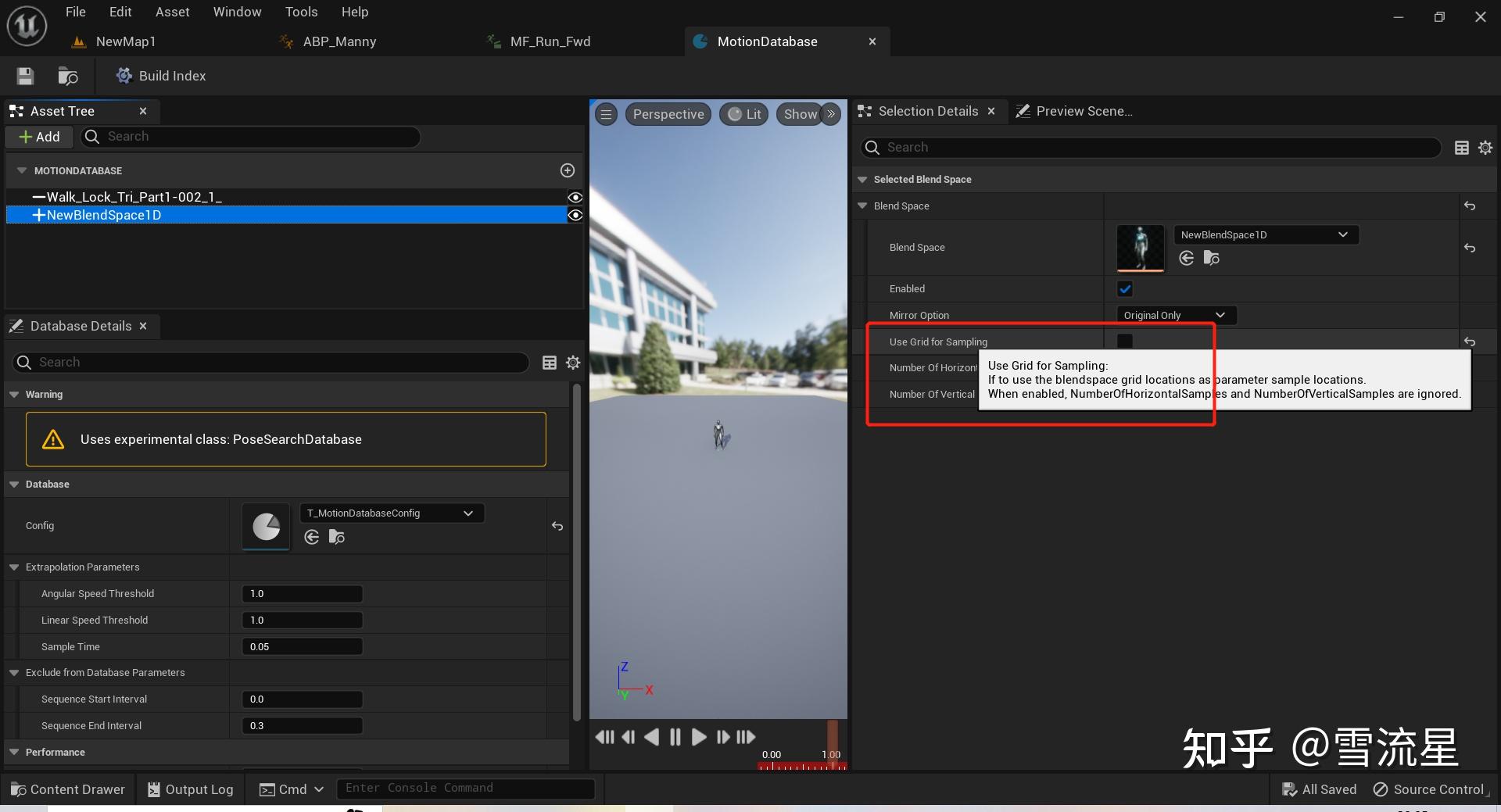
使用BlendSpace的方式和Sequence一样,不过需要指定采样方式,默认选择Use Grid for Sampling,根据Blend Space格子进行采样,也可以手动指定采样位置。采样数量就是Number Of Horizontal Samples*Number Of Vertical Samples,设置越大,采样的Pose数量也就越多。
使用镜像数据表
使用镜像数据表的方式也比较简单,但需要注意的是,Pose数量会翻倍,首先是在数据库中选择一个Sequence
的mirror option设为支持镜像
然后特征数据表配置镜像数据表,关于镜像数据表,参考官方文档就好了。

总结
到此,MotionMatching的原理和如何调参说的差不多了,但这只是做完了一般而已,另一半是如何录制标准的动补运动数据,当然最标准的就是动画师手k了,如果真让动画师k我相信动画师会打死你的(开个玩笑),那么关于关于录制动补和数据处理,也是比较多细节需要处理的,尤其是根运动数据,涉及的东西还挺多的。
下面是一个UE5.1 MotionMatching的demo:

另外,虚幻5关于动画方面的发展,个人感觉趋势就是希望动画不断往程序化的方向发展,以后还会有哪些出色功能呢,拭目以待。 |
|

